6.1 텍스트 파일에서 데이터를 읽고 쓰기
보통 read_csv, read_table을 많이 쓴다. 텍스트 데이터를 DataFrame으로 읽어올 때 아래와 같은 옵션들을 설정할 수 있다.
1) 색인:
반환하는 DataFrame에서 하나 이상의 컬럼을 색인으로 지정할 수 있다. (지정안해도됨)
2) 자료형 추론과 데이터 변환:
사용자 정의 값 변환과 비어있는 값을 위한 사용자 리스트를 포함한다.
3) 날짜 분석:
여러 컬럼에 걸쳐있는 날짜와 시간 정보를 하나의 컬럼에 조합한다.
4) 반복:
여러 개의 파일에 걸쳐 있는 자료를 반복적으로 읽어올 수 있다.
5) 정제되지 않은 데이터 처리:
로우나 꼬릿말, 주석 건너뛰기 또는 천 단위마다 쉼표로 구분된 숫자같은 사소한 것들의 처리
이외에도 read_csv의 경우 함수 인자가 50개가 넘는다. 특정 파일을 읽는 데 어려움을 느끼면 찾아봐야 함.
아래와 같은 csv파일로 실습

여러가지 방법으로 읽어오기
df1 = pd.read_csv('examples/ex1.csv')
df2 = pd.read_csv('examples/ex1.csv', header=None)
df3 = pd.read_csv('examples/ex1.csv', names = ['a','b','c','d','message'])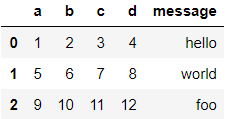


index_col 인자로 컬럼을 색인으로 만들 수 있다.
df4 = pd.read_csv('examples/ex1.csv', index_col = 'message')
6.1.1 텍스트파일 조금씩 읽어오기
아래와 같이 생긴 데이터로 실습

첫 몇 줄만 읽어보고 싶다면 nrows 옵션을 주면 된다.
pd.read_csv('examples/ex6.csv', nrows=5)
파일을 여러 조각으로 나눠서 읽고싶다면 chunksize의 옵션으로 로우의 개수를 주면 된다. 이 때 반환되는 것은 DataFrame이 아니라 TextParser객체이다. 이 파서객체를 이용해 chunksize에 따라 분리된 파일들을 순회할 수 있다.
ex) 'key' 로우에 있는 값을 센 도수분포표 만들기
chunker = pd.read_csv('examples/ex6.csv', chunksize=1000)
chunker
#<pandas.io.parsers.TextFileReader at 0x21080011da0>
tot = pd.Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
tot = tot.sort_values(ascending = False)
tot
#E 368.0
#X 364.0
#L 346.0
#O 343.0
#Q 340.0
# ...
#5 157.0
#2 152.0
#0 151.0
#9 150.0
#1 146.0
#Length: 36, dtype: float64
TextParser는 임의 크기 조각을 읽을 수 있는 get_chunk 메서드도 있음.
6.1.2 데이터를 텍스트 형식으로 기록하기
DataFrame의 to_csv 메서드를 이용하면 데이터를 쉼표로 구분된 형식으로 파일에 쓸 수 있다.
쉼표 대신 다른 구분자를 쓰려면 sep옵션에 문자를 하나 넘기면 된다.

sys,stdout에 결과를 쓰도록 할 수도 있다.
import sys
data.to_csv(sys.stdout, sep='|')
#|something|a|b|c|d|message
#0|one|1|2|3.0|4|
#1|two|5|6||8|world
#2|three|9|10|11.0|12|foo
결과에서 누락된 값은 기본적으로 빈 문자열로 나타난다. na_rep옵션에 원하는 값을 지정해줄 수 있다.
data.to_csv(sys.stdout, na_rep='NULL')
,something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo위 예제에서 something 옆에 빈 칸인 이유는 맨 윗줄을 컬럼으로 쓰는 것으로 해석하기 때문인듯 하다.
로우와 컬럼의 이름을 포함하지 않을 수 있다. index, header옵션을 False로 주면 된다.
data.to_csv(sys.stdout, index=False, header=False)
#one,1,2,3.0,4,
#two,5,6,,8,world
#three,9,10,11.0,12,foo
컬럼의 일부분만 기록할 수도 있다. 순서를 직접 지정할 수 있다.
data.to_csv(sys.stdout, index=False, columns=['a','b','c'])
#a,b,c
#1,2,3.0
#5,6,
#9,10,11.0
Series에도 to_csv 메서드가 존재한다.
dates = pd.date_range('1/1/2000', periods=7)
ts = pd.Series(np.arange(7), index=dates)
ts.to_csv(sys.stdout)
#2000-01-01,0
#2000-01-02,1
#2000-01-03,2
#2000-01-04,3
#2000-01-05,4
#2000-01-06,5
#2000-01-07,6
6.1.3 구분자 형식 다루기
pandas.read_table 함수를 이용해서 디스크에 표 형태로 저장된 대부분의 파일 형식을 불러올 수 있다. 하지만 read_table함수가 데이터를 불러오는 데 실패하게끔 만드는 라인이 포함돼 있는 데이터를 전달받는 경우가 있다.
데이터가 다음과같이 저장된 csv 파일을 생각해보자.

위 csv파일을 read_table로 읽어오게 되면 부정확한 데이터가 DataFrame에 담기게 된다.

구분자가 한 글자인 파일은 파이썬 내장 csv 모듈을 이용해서 처리할 수 있다. 열려진 파일 객체를 csv.reader함수에 넘기기만 하면 된다.
import csv
f = open('examples/ex7.csv')
reader = csv.reader(f)
for line in reader:
print(line)
#['a', 'b', 'c']
#['1', '2', '3']
#['1', '2', '3']
원하는 형태로 데이터를 넣을 수 있도록 해보자. 먼저 파일을 읽어 line단위 리스트로 저장한다. 그리고 헤더와 데이터를 구분한다. 그리고 사전표기법과 로우를 컬럼으로 전치해주는 zip(*values)를 이용해서 데이터 컬럼 사전을 만들 수 있다.
with open('examples/ex7.csv') as f:
lines = list(csv.reader(f))
header, values = lines[0], lines[1:]
data_dict = {h:v for h,v in zip(header, zip(*values))}
data_dict
#out : {'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}
6.1.4 JSON 데이터
JSON(javascript object notation)은 웹브라우저와 다른 애플리케이션이 HTTP 요청으로 데이터를 보낼 때 많이 사용하는 파일 형식 중 하나다.
JSON 데이터의 예
obj = """
{"name": "Wes",
"places_lived": ["United States", "Spain", "Germany"],
"pet": null,
"siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]},
{"name": "Katie", "age": 38,
"pets": ["Sixes", "Stache", "Cisco"]}]
}
"""
JSON은 파이썬 코드와 유사하다. 기본 자료형은 객체(사전), 배열, 문자열, 숫자, 불리언, 그리고 널이다. 객체의 키는 반드시 문자열이어야 한다. 파이썬 표준 라이브러리인 json을 사용해서 읽고 쓸 수 있다. JSON 문자열을 파이썬 형태로 변환하기 위해선 json.loads를 사용한다.
json.dumps는 파이썬 객체를 JSON 형태로 변환한다.

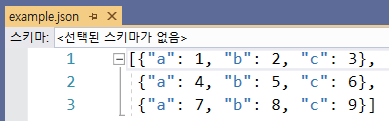
위 result에서 sibling에 대한 DataFrame을 만들면 다음과 같다.

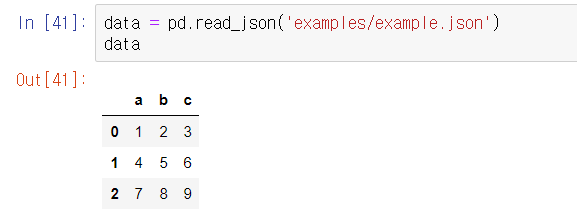
pandas.read_json은 json배열에 담긴 각 객체를 테이블의 로우로 간주한다
pandas데이터를 JSON으로 저장하려면 Series, DataFrame의 to_json함수를 이용하면 된다.

6.1.5 XML과 HTML : 웹 스크래핑
파이썬에는 HTML, XML형식의 데이터를 읽고 쓸 수 있는 라이브러리가 많다. 그 중 lxml을 가장 많이 쓴다.
pandas에는 read_html로 HTML을 자동으로 파싱하여 DataFrame으로 변환해준다. 기본적으로 <table> 태그 안에 있는 모든 표 형식의 데이터 파싱을 시도한다. 결과는 DataFrame 객체의 리스트에 저잔된다.

XML(eXtensible Markup Language)은 계층적 구조와 메타데이터를 포함하는 중첩된 데이터 구조를 지원하는 형식이다. HTML과 구조적으론 유사하지만 XML이 더 범용적이다.
256pg~
6.2 이진 데이터 형식
데이터를 효율적으로 저장하는 가장 손쉬운 방법은 파이썬 내장 pickle 직렬화를 사용해서 데이터를 이진형식으로 저장하는 것이다. pandas 객체는 모두 pickle을 이용해서 데이터를 저장하는 to_pickle 메서드를 가지고 있다.

pickle로 저장한 데이터는 라이브러리의 버전이 올라갔을 때 다시 읽어오지 못하는 경우가 있어서 주의해야 한다.
pandas는 HDF5와 message-pack, 두 가지 바이너리 포맷을 지원한다.
6.2.1 HDF5 형식 사용하기
과학 계산용 배열 데이터에 최적화. 다른 많은 언어에서도 사용할 수 있는 인터페이스 제공. Hierarchical Data Format의 약자로 계층적 데이터 형식이라는 뜻이다. on-the-fly(실시간) 압축을 지원하며 반복되는 패턴을 가진 데이터를 효과적으로 저장한다. 아주아주 큰 데이터의 아주 큰 배열에서 필요한 작은 부분들만 효과적으로 읽고 쓸 수 있다.
pandas에선 Series나 DataFrame객체로 간단히 저장할 수 있는 인터페이스를 제공한다. HDFStore 클래스는 사전처럼 작동한다.

GDFStore은 'fixed'와 'table' 두 가지 저장 스키마를 지원한다. table 스키마의 경우 다음과 같은 특별한 문법을 이용해 쿼리 연산을 지원한다. put은 store['obj2']=frame과 의미는 같지만 저장 스키마를 지정하는 등의 옵션을 제공한다.

pandas.read_hdf 함수는 이런 기능들을 축약해서 사용할 수 있다.

6.2.2 마이크로소프트 엑셀 파일에서 데이터 읽어오기
pandas는 ExcelFile 클래스나 pandas.read_excel 함수를 사용해서 엑셀2003 이후 버전의 데이터를 읽어올 수 있다. 내부적으로 xlrd, openpyxl 패키지를 이용하므로 두 패키지를 설치해야 한다.
한 엑셀 파일에서 여러 번 읽을 필요가 있는 경우(여러 sheet를 읽을 필요있다면) ExcelFile객체를 생성하는 편이 낫다.

pandas 데이터를 엑셀 파일로 저장하고 싶다면 ExcelWriter객체를 생성해서 데이터를 기록하고 pandas 객체의 to_excel 메서드로 넘기면 된다. 역시 ExcelWriter객체 사용하지 않고 파일 경로만 넘겨도 된다.

6.3 웹 API와 함께 사용하기
데이터 피드를 JSON이나 여타 다른 형식으로 얻을 수 있는 공개 API를 제공하는 웹사이트가 많다. 파이썬으로 이 API를 사용하는 방법은 다양한데, requests 패키지를 이용하는 것이 좋다.
pandas 깃허브에서 최근 30개의 이슈를 가져오려면 requests 라이브러리를 이용해서 다음과 같은 GET HTTP 요청을 생성하면 된다. 응답 객체의 json 메서드는 JSON의 내용을 파이썬 사전 형태로 변환한 객체를 반환한다.

data의 각 항목은 깃허브 이슈페이지(댓글 제외)에서 찾을 수 있는 모든 데이터를 담고 있따. 이 data를 바로 DataFrame으로 생성하고 관심이 있는 필드만 따로 추출할 수 있다.

6.4 데이터베이스와 함께 사용하기
파이썬 내장 sqlite3 드라이버를 사용해서 SQLite 데이터베이스를 이용할 수 있다. 대부분의 SQL 드라이버는 테이블에 대해 select 쿼리를 수행하면 튜플 리스트를 반환한다.

반환된 튜플 리스트를 DataFrame생성자에 바로 전달해도 되지만, 컬럼 이름을 지정해주면 더 편하다. cursor의 description 속성을 활용하자.

데이터베이스에 쿼리를 보내기 위해 매번 이렇게 stmt를 작성하고 query를 생성하여 commit, fetch하는 것은 귀찮은 일이다. SQL 툴킷인 SQLAlchemy 프로젝트는 SQL 데이터베이스 간의 일반적인 차이점을 추상화하여 제공하낟. pandas는 read_sql함수를 제공하여 SQLAlchemy의 일반적인 연결을 통해 쉽게 데이터를 읽을 수 있도록 한다.

'ML&DATA > python for data analysis' 카테고리의 다른 글
| pandas - (데이터 준비하기: 조인, 병합, 변형) (0) | 2020.07.24 |
|---|---|
| pandas - (데이터 정제 및 준비) (0) | 2020.07.22 |
| pandas - (기술 통계 계산) (0) | 2020.07.21 |
| pandas - (재색인, 중복 색인 등 핵심 기능) (0) | 2020.07.20 |
| pandas - (Series, DataFrame, Index) (0) | 2020.07.19 |



