8.1 계층적 색인
축에 대해 다중 색인 단계를 지정할 수 있다. 높은 차원의 데이터를 낮은 차원의 형식으로 다룰 수 있도록 하는 기능이다.
MultiIndex를 색인으로 하는 Series 예
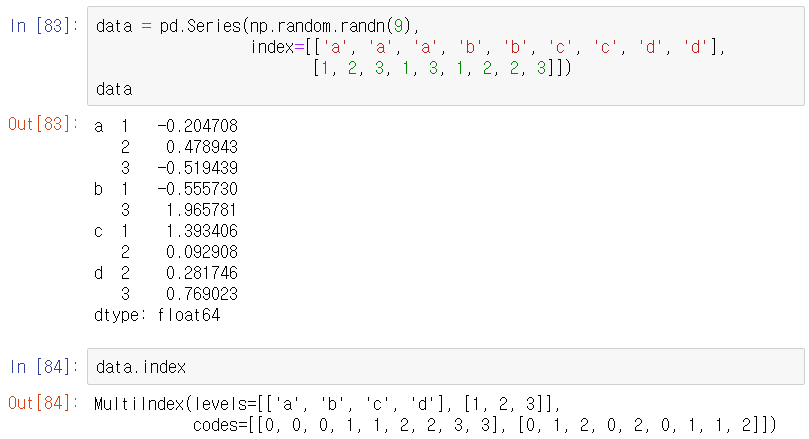
계층적으로 색인된 객체는 데이터의 부분집합을 부분적 색인(partial indexing)으로 접근하는 것이 가능하다

iloc사용과 헷갈리면 안된다.

Series객체인 data에 unstack메서드를 사용해서 데이터를 DataFrame타입으로 새롭게 배열할 수 있다.
unstack의 반대작업은 stack메서드로 수행한다.

DataFrame에서는 두 축 모두 계층적 색인을 가질 수 있다. 계층적 색인의 각 단계는 이름을 가질 수 있다.


8.1.1 계층의 순서를 바꾸고 정렬하기
Series, DataFrame의 swaplevel메서드느 넘겨받은 두 개의 계층 이름이 뒤바뀐 새로운 객체를 반환한다.

sort_index메서든느 단일 계층에 속한 데이터를 정렬한다.

8.1.2 계층별 요약 통계
DataFrame과 Series의 많은 기술 통계와 요약 통계는 level옵션을 가지고 있다. 이는 내부적으로 pandas의 groupby라는 기능을 이용해서 구현됐다.

8.1.3 인덱스로 DataFrame의 컬럼 사용하기
DataFrame의 set_index함수는 프레임의 컬럼을 선택하여 인덱스로 삼은 객체를 반환한다.
drop=False옵션을 주면 컬럼도 그대로 길 수 있다.

reset_index() 함수는 set_index와 반대되는 개념이다. 계층적 색인이 컬럼으로 이동한다.

8.2 데이터 합치기
pandas.merge : 하나 이상의 키를 기준으로 DataFrame의 로우를 합친다. sql의 join연산과 비슷
pandas.concat : 하나의 축을 따라 객체를 이어붙인다.
combile_first 인스턴스 메서드 : 두 객체를 포개서 한 객체에서 누락된 데이터를 다른 객체에 있는 값으로 채울 수 있도록 한다.
8.2.1 데이터베이스 스타일로 DataFrame합치기
merge는 기본적으로 중복된 컬럼 이름을 키로 사용하지만 명시적으로 on옵션을 넘겨주는 것이 좋다.
기본적으로 내부조인을 수행한다. left outer join, right outer join, outer join 등을 원한다면 how옵션을 넘겨주면 된다.


만약 두 객체에 중복된 컬럼 이름이 하나도 없다면 따로 지정해줘야 한다.

여러 개의 키를 병합하려면 컬럼 이름이 담긴 리스트를 넘기면 된다.

merge 연산 시 키로 사용하지 않지만 겹치는 컬럼 이름이 있다면 기본적으로 다음과 같이 이름붙여 수행된다.

접미사로 _x,_y대신 다른 것을 사용하고 싶다면 suffixes 옵션에 튜플을 넘기면 된다.

8.2.2 색인 병합하기
병합하려는 키가 DataFrame의 인덱스인 경우 left_index=True 또는 right_index=True 옵션으로 해당 색인을 병합 키로 사용할 수 있다.


계층 색인된 데이터는 암묵적으로 여러 키를 병합한다. 이 경우 리스트로 여러 개의 컬럼을 지정해서 병합해야 한다.

양쪽에 공통적으로 존재하는 여러 개의 색인을 병합하는 것도 가능하다.

색인으로 병합할 때 DataFrame의 join 메서드를 사용하면 편하다. join 메서드는 컬럼이 겹치지 않으며 완전히 같거나 유사한 색인 구조를 가진 여러 개의 DataFrame 객체를 병합할 때 사용할 수 있다.

색인 대 색인으로 두 DataFrame을 병합하려면 병합하려는 DataFrame의 리스트를 join메서드로 넘기면 된다. 하지만 보통 concat을 많이 사용한다.

8.2.3 축 따라 이어붙이기
concatenation, binding, stacking이라고도 한다. numpy는 ndarray를 이어붙이는 concatenate함수 제공한다.

Series나 DataFrmae같은 pandas의 객체의 컨텍스트 내부엔 축마다 이름이 있어서 배열을 쉽게 이어붙일 수 있도록 돼 있다. 이 때 고려해야할 사항은 다음과 같다.
1) 연결하려는 두 객체의 색인이 다르면 결과는 그 색인의 교집합/합집합?
2) 합쳐진 결과에서 합쳐지기 전 객체의 데이터를 구분할 수 있어야 하는지?
3) 어떤 축으로 연결할 것인지?
pandas의 concat함수는 위 사항을 모두 고려하여 만들어졌다.


기본적으로 외부 조인의 형식으로 정렬된 합집합을 얻었지만, join='inner'를 넘겨서 교집합을 구할 수 있다.
join_axes인자로 병합하려는 축을 직접 정해줄 수도 있다.

위와 같은 방법으론 이어 붙이기 전의 상태를 구분할 수 없는 문제가 있다. 이어붙인 축에 대해 계층적 색인을 생성하여 식별할 수 있도록 할 수 있다. 계층적 색인을 생성하려면 keys인자를 사용하면 된다.

DataFrame객체에 대해서도 지금까지와 같은 방식으로 적용할 수 있다.

계층적 색인을 생성할 때 여러가지 옵션을 선택할 수 있다. objs(이어붙일 pandas객체의 사전이나 리스트, 필수인자임), axis, join, join_axes, keys, levels, names, verify_integrity, ignore_index등)
예를 들어 새로 생성된 계층의 이름은 names 인자로 지정할 수 있다.

8.2.4 겹치는 데이터 합치기
데이터를 합칠 때 두 데이터셋의 인덱스가 일부 겹치는 경우 병합이나 이어붙이기로 불가능한 상황이 있다.
벡터화된 if-else구문(삼항연산자와 유사함)을 표현하는 numpy의 where함수로 자세히 알아보자

Series객체의 combine_first 메서드는 위와 동일한 연사을 제공하며, 데이터정렬까지 해준다.

DataFrame의 combine_first메서드는 컬럼에 대해 동작한다. 호출하는 객체에서 누락된 데이터를 인자로 넘긴 객체에 있는 값으로 채울 수 있다.

8.3 재형성과 피벗
표 형식의 데이터를 재배치하는 다양한 연산이 존재한다. 이런 연산을 재형성 또는 피벗연산이라고 한다.
8.3.1 계층적 색인으로 재형성하기
계층적 색인은 DataFrame의 데이터를 재배치하는 다음과 같은 방식을 제공한다.
1) stack : 데이터의 컬럼을 로우로 피벗(또는 회전)시킨다.
2) unstack : 로우를 컬럼으로 피벗시킨다.
stack메서드를 사용하면 다음과같이 컬럼이 로우로 피벗된다. unstack하면 다시 로우를 컬럼으로 피벗한다.
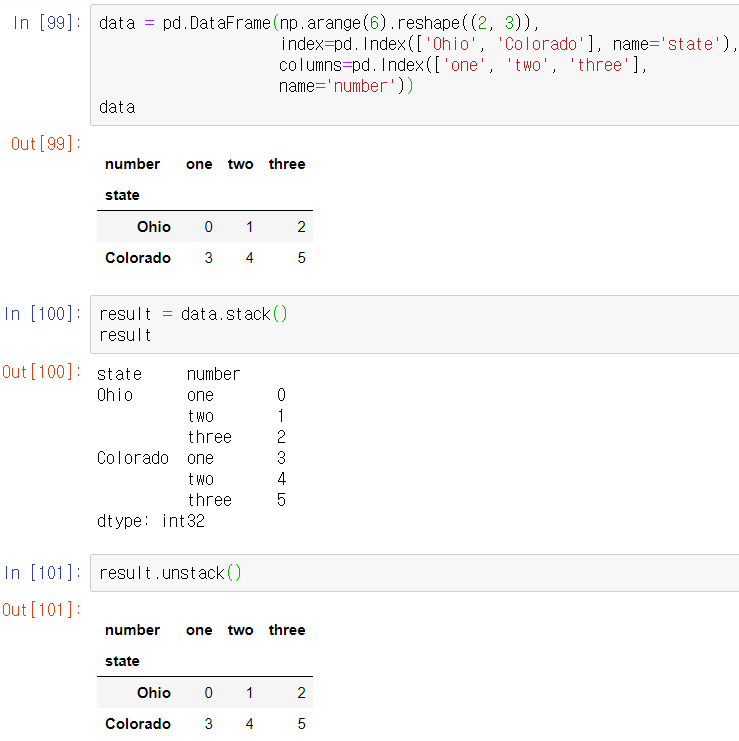
기본적으로 가장 안쪽에 있는 레벨부터 끄집어내는데, 레벨 숫자나 이름을 전달해서 끄집어낼 단계를 지정할 수 있다.

해당 레벨에 있는 모든 값이 하위 그룹에 속하지 않을 경우 unstack을 하게되면 누락된 데이터가 생길 수 있다
stack 메서드는 누락된 데이터를 자동으로 걸러내기 때문에 쉽게 원상복구할 수 있다.

DataFrame을 unstack할 때 레벨은 결과에서 가장 낮은 단계가 된다.

8.3.2 긴 형식에서 넓은 형식으로 피벗하기
db나 csv에 여러 개의 시계열 데이터는 시간 순서대로 나열하여 저장한다.
예제로 시계열 데이터를 다뤄보자.

굉장히 많은 특성들을 확인할 수 있는데, 이 중 일부 컬럼만 사용할 것이다.
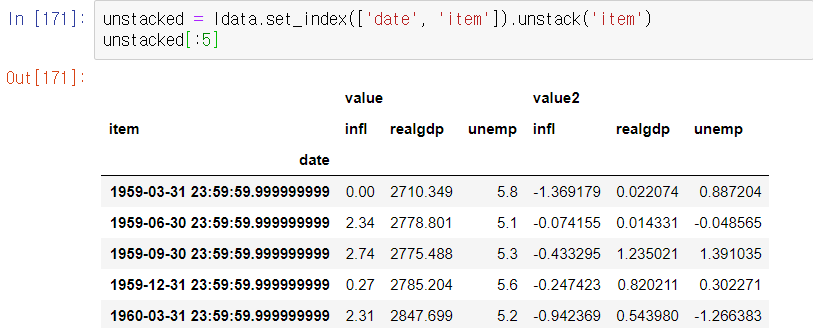
pd.PeriodIndex는 시간 간격을 나타내기 위한 자료형으로, 연도(year)와 분기(quarter)컬럼을 합친다
인덱스를 PeriodIndex를 활용해 정의한 'date', 컬럼은 'realgdp', 'infl', 'unemp'를 사용한다.

realgdp, infl, unemp를 row로 옮기고 0부터시작하는 index를 매기면 다음과 같다. 그러면 하나의 시간에 세가지 정보가 세 로우에 걸쳐 보여진다.

이를 긴 형식이라고 한다. 여러 시계열이나 둘 이상의 키(예제에선 date, item)을 가지고 있는 다른 관측 데이터에서 사용한다. 각 로우는 단일 관측치를 나타낸다.
관계형 데이터베이스는 테이블에 데이터가 추가되거나 삭제되면 item컬럼에 별개이 값을 넣거나 뺴는 방식으로 고정된 스키마(컬럼 이름과 데이터형)에 데이터를 저장한다. 위 예에서 date와 item은 db관점에선 primary key가 되어 관계 무결성을 제공하며 쉬운 조인 연산과 프로그램에 의한 질의를 가능하게해준다. 물론 단점도 있는데, 길이가 긴 형식으로는 작업이 용이하지 않을 수 있어서 하나의 DataFrame에 date컬럼의 시간값으로 인덱싱된 개별 item을 컬럼으로 포함시키는 것을 선호할지도 모른다. DataFrame의 pivot메서드가 이런 변형을 지원한다.
pivot메서드의 처음 두 인자는 로우와 컬럼 색인으로 사용될 컬럼 이름이고 마지막 두 인자는 DataFrame에 채워 넣을 값을 담고있는 컬럼 이름이다.

마지막 인자를 생략해서 계층적 컬럼을 가지는 DataFrame을 얻을 수 있다.


pivot을 다시 말하면 set_index로 계층적 색인을 만들고 unstack으로 형태를 변경하는 것과 같다.
8.3.3 넓은 형식에서 긴 형식으로 피벗하기
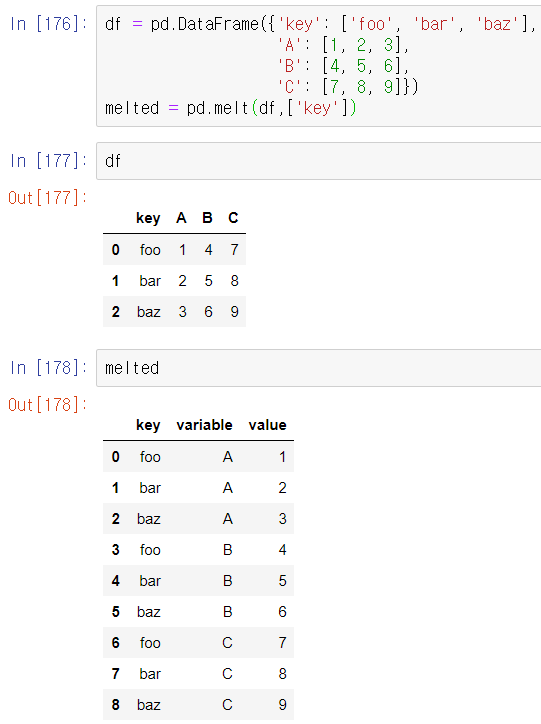
pivot과 반대되는 연산은 pandas.melt다. 하나의 컬럼을 여러 개의 새로운 DataFrame으로 생성하는 것이 아니고, 여러 컬럼을 하나로 병합하고 DataFrame을 입력보다 긴 형태로 만들어 낸다.
'어떤 컬럼을 그룹 구분자로 사용할 수 있고 다른 컬럼들(variable)을 데이터값(value)으로 사용할 수 있다. pandas.melt를 사용할 때는 반드시 어떤 컬럼을 그룹 구분자로 사용할 것인지 지정해야 한다.
(melted = pd.melt(df, id_vars=['key'])에서 id_vars가 생략됐다.)
pivot을 사용해서 원래 모양으로 되돌릴 수도 있다. 다만 pivot의 결과는 로우라벨로 사용하던 컬럼에서 색인을 생성하므로 reset_index를 이용해서 데이터를 다시 컬럼으로 되돌려야 한다.

데이터값으로 사용할 컬럼들의 집합을 지정할 수도 있다.

pandas.melt는 그룹 구분자 없이도 사용할 수 있다.

'ML&DATA > python for data analysis' 카테고리의 다른 글
| 그래프의 시각화 - (matplotlib, pandas, seaborn) (0) | 2020.07.28 |
|---|---|
| pandas - (데이터 정제 및 준비) (0) | 2020.07.22 |
| pandas - (데이터 로딩과 저장, 파일 형식) (0) | 2020.07.21 |
| pandas - (기술 통계 계산) (0) | 2020.07.21 |
| pandas - (재색인, 중복 색인 등 핵심 기능) (0) | 2020.07.20 |



