내용이 워낙 방대해서 기본적인 부분만 정리. 더 찾아볼만한 건 하단에 따로 용어 정리
OSI 7 layer :
국제표준화기구(ISO)에서 개발한 모델로, 컴퓨터 네트워크 프로토콜 디자인과 통신을 계층으로 나누어 설명한 것
tcp/ip protocol suite(인터넷 프로토콜 스위트) :
OSI 7 layer보다 먼저 개발됨. 이 모델로 tcp/ip를 이해하는 것이 더 쉬움.

Application layer : src application -> dest application
[message]
Transport Layer : src port -> dest port
[segment]
Network layer : src ip -> dest ip
[datagram]
datalink layer : hop -> hop (라우터에서 라우터로)
[frame]
<TCP> transmission control protocol
헤더:
헤더에 어떤 정보가 담기는 지 알면 TCP의 역할을 유추할 수 있다.
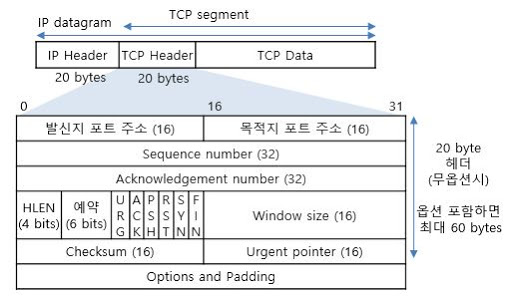
옵션에선 mss를 정하거나 scale factor(윈도우 크기 더 크게 보내기)를 정하는 등의 일을 함.
ack:
tcp에서 보내는 패킷(세그먼트)마다 번호(sequence number)를 붙인다.
패킷을 받는 쪽에서 다음에 받을 번호를 보내주는데, 이 번호를 acknowledgment number라고 함.
three-way handshake:
연결 셋업 과정을 SYN - SYN+ACK - SYN으로 나타낸 것. 연결 종료과정도 비슷하게 표현 가능
리눅스 상에선..
1. 클라이언트는 connect함수로 SYN 패킷을 보냄
2. 서버의 accept함수는 SYN을 받고 SYN+ACK을 보냄
3. 클라이언트의 connect 함수는 SYN+ACK을 받고 ACK 보낸 후 return
4. 서버의 accept는 ACK받고 return

window size:
얼만큼 데이터를 받을 수 있는지 헤더에 같이 보냄.
버퍼와 관련된 rwnd와 혼잡제어(congestion control, 라우터의 용량)과 관련된 cwnd 중 작은 값을 선택해서 보냄.
receiver의 버퍼 소비속도에 맞게 rwnd를 만들고 보내는 과정을 흐름제어(flow control)라고 함.
silly window syndrome: 송신측에서 1byte씩만 데이터를 보내면 낭비가 심하다. (데이터는 작은데 패킷은 큼)
송신측 문제 - 1byte씩만 데이터 보내면 낭비가 심함
1. 첫 데이터는 바로 보냄
2. 버퍼에 MSS(maximum segment size)만큼 쌓이면 바로 보냄
3. 예전에 보낸 데이터에 대한 ACK받으면 바로 보냄
(위 과정을 naggle algorithm이라고 함. 버퍼에 데이터 들어오면 바로 보내지 않고 모았다 보내는게 핵심)
수신측 문제 - 어떤 이유로 receiver의 app이 버퍼에서 1byte씩만 소비한다면 sender에게 ACK rwnd=1을 계속보내서 sender가 1byte씩만 보낼 수 있음.
해결1(clark's algorithm) : receiver버퍼에 일정 공간이 생기기 전까진 ACK rwnd=0보낸다.
해결2(확인응답의 지연) : receiver버퍼에 일정 공간이 생기기 전까진 ACK보내지 않음
syn flooding:
SYN(연결요청)을 계속 받다보면 큐가 가득 차서 서비스 못해줌. (DoS : denial of serviece)
<UDP>User Datagram Protocol
UDP의 전송 방식은 너무 단순해서 서비스의 신뢰성이 낮고, 데이터그램 도착 순서가 바뀌거나, 중복되거나, 심지어는 통보 없이 누락시키기도 한다. UDP는 일반적으로 오류의 검사와 수정이 필요 없는 애플리케이션에서 수행할 것으로 가정한다.
데이터 경계 존재, 연결 셋업과정이 없어서 데이터 분실 및 손실 위험 존재, 전송이 빠름, 신뢰성보장 안함, flow control 안함, congestion control 안함
헤더:

<추가>
tcp의 stream delivery(<->boundary delivery, 데이터의 경계유무). sending process가 버퍼에 쓰면 스트림이 가져가서 receiving process의 버퍼에 쓰고 receiving 프로세스가 그 버퍼에서 읽어서 버퍼를 비우는 과정.
selective ack:
장점 - sender에게 순서에 어긋난 데이터를 알려줌
단점 - 패킷 크기가 커짐
cumulative ack:
장점 - sender측 윈도우 조정 용이
단점 - packet loss 이후의 상황을 자세히 알 수 없다
혼잡제어와 흐름제어
연결 종료시에도 3-way handshake 꼴로 이뤄짐
FIN 수신받고 TIME-WAIT state로 2MSL 대기함
- 마지막 ACK전송이 실패한 경우 ACK 못받은 쪽에서 FIN을 다시 전송하게 돼 있음. 이거 기다리려구
- 2MSL대기하지 않는다면, 같은 IP, PORT번호를 가진 클라이언트가 연결 종료 직후 다시 새로 연결한 경우 이전 연결에 전송됐던 데이터와 새로 연결된 데이터를 구분 못하는 문제 발생
ACK을 줄이기 위한 여러 방법이 사용됨. (ack과 데이터전송을 같이 하는 등)
1. ACK 보낼 때 sending buffer에 보낼 데이터가 있고 receiver의 window size가 여유 있다면 데이터를 같이 보냄.
2. ACK 보내야 하는데 현재 데이터를 보낼 수 없다면 500ms까지 대기
3. rule2에 의해 대기 중 다른 패킷을 받으면 그만 기다리고 ACK 전송
ACK전송 시 에러 컨트롤
1. 패킷 loss detect나 out of order 검출 시 바로 ACK 전송
2. 잃어버린 패킷 받은 후 바로 ACK
3. 중복된 패킷 받은 후 바로 ACK
fast retransmission
도입 이유: cummulative ack에선 packet loss 이후의 상황을 자세히 알 수 없으므로 packet loss를 보다 빨리 detect하고자 도입함.
설명: sender는 3개의 중복된 ACK을 받으면 패킷loss가 발생했다고 간주하고 해당 ACK에 맞는 데이터 즉시 전송
persistenet timer 사용 이유:
특정 경우 packet loss가 발생하면 영원히 기다리는 deadlock이 발생할 수 있음.

흐름제어를 위해 persistence timer, keepalive timer, retransmission timer 등 사용함
'CS > 컴퓨터네트워크' 카테고리의 다른 글
| TCP/IP (2) (0) | 2020.12.22 |
|---|---|
| [열혈] 멀티쓰레드 기반 서버구현 (0) | 2020.12.22 |
| [열혈] 멀티플렉싱 기반 서버구현 (0) | 2020.11.24 |
| [열혈] 멀티 프로세스 기반 서버구현 (2) | 2020.10.25 |
| [열혈] dns (0) | 2020.10.24 |



