Ch1. Why PyTorch
1.3.1 The deep learning competitive landscape
2017년)
- pytorch 베타 릴리즈
- TensorFlow는 low-level 라이브러리로 사용
- Keras는 TensorFlow의 high-level Wrapper
2019년)
- PyTorch
- Caffe2를 백엔드로 흡수.
- ONNX 자체 지원
- TorchScript cnrk
- TensorFlow
- Keras 흡수, first-class API로 제공
1.4 Overview of how PyTorch supports DL projects
pytorch는 C++과 CUDA프로그래밍 된 부분이 있음. PyTorch를 C++기반으로 바로 실행시키는 방법 ch15에 소개.
tensor의 연산자 라이브러리는 torch모듈에 존재. CPU, GPU모두에서 사용 가능. 전환이 코드 한 두줄 정도로 간단하다.
탠서는 수행한 연산을 추적할 수 있다. 인풋별로 분석도 가능한듯. 이건 PyTorch의 'autograd'엔진에 기반한 numerical 최적화에 사용된다.
torch.nn모듈에 뉴럴네트워크 레이어와 다른 구조적 컴포넌트가 포함돼 있다. loss funtion, activation function같은 것도 포함됨.

위 그림과 같이 스토리지에서 데이터를 가져올 때 tensor형태로 바꾸고 batch로 묶어주는데, PyTorch는 이걸 Dataset, DataLoader 클래스로 제공함.(ch7)
autograd engine은 training에 관여함. 이때 torch.optim에 정의된 optimizer들이 필요함. (ch5)
멀티gpu, 멀티노드 트레이닝 시 torch.nn.parallel.Distributed-DataParallel, torch.distributed 모듈을 사용한다.
Torchscript로 모델을 instruction의 셋으로 직렬화해서 Python이 아닌 C++프로그램이나 모바일 기기에서 사용할 수 있도록 할 수 있다. 파이토치에서 TorchScript와 ONNX변환은 제품 배포의 기본이다. (ch15)
Ch2. Pretrained Networks
생략
Ch3. It Starts with a tensor
3.1 floating-point numbers
floating-point number는 네트워크가 정보를 처리하는 방식이므로, real-world 데이터를 네트워크가 소화할 수 있는 floating point number로 인코딩하고, 그걸 다시 디코딩해서 우리가 이해할 수 있는 형태의 데이터로 되돌릴 수 있어야 한다.
NN에서 데이터를 한 형식에서 다른 형식으로 변환하는 과정을 반복하는데, 각 데이터의 데이터는 Intermediate representation 이라고 생각할 수 있다.
Tensor는 multidimensional array이다. arr[0]처럼 tens[0,3,1]이런식으로 랜덤엑세스 가능하다.
Numpy도 마찬가지로 multidimensional array이다. Tensor와 seamless interoperability를 갖는다.
Tensor는 Numpy와 다르게 GPU에서 빠른 연산, 멀티노드 분산 연산, 연산 추적 등이 가능하다.
3.2 Tensors: Multidimensional arrays
PyTorch tensors나 NumPy는 `unboxedC` 뉴메릭 타입을 갖는 연속된 메모리 블럭을 본다(view). (리스트나 튜플같은 파이썬 오브젝트는 각자 메모리에 할당됨).
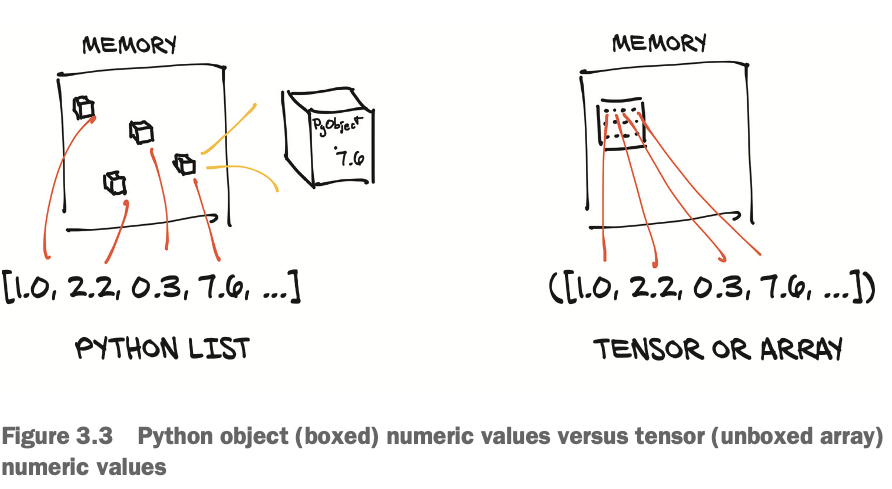
32bit(4byte) float number 1,000,000개의 tensor는 연속된 4,000,000byte + 메타데이터의 용량이 필요하다.
텐서도 파이썬 리스트와 마찬가지로 슬라이싱 가능함. tens[None]은 unsqueeze와 유사하게 1차원 높여주는 역할을 한다.
텐서로 행렬연산을 하다보면 축(차원)에 이름을 붙이면 편한 경우가 많이 생긴다. 이 때, einsum 표기법을 사용하거나 named tensor(1년 반째 개발중)를 사용하면 된다.
3.5 Tensor element types
2020기준, half-precision(16bit) dtype은 CPU에서 제공하지 않음. GPU에선 제공함.
텐서는 다른 텐서의 인덱스로 사용할 수 있는데, 64bit 정수 data type이어야 한다.
dtype을 지정하는 건 세가지 방법으로 가능
double_points = torch.ones(10, 2, dtype=torch.double)
double_points = torch.zeros(10, 2).double()
double_points = torch.zeros(10, 2).to(torch.double)
특히 'to'를 사용하는 경우 전환이 필요한지 확인후 필요하다면 전환함. 그리고 추가적인 argument지정 가능(device)
다른 타입의 텐서를 연산하도록 하면 큰 타입 쪽으로 자동 변환됨.
3.6 The Tensor API
텐서 연산은 다음과 같은 그룹들로 나뉜다.
생성 연산 - ones, from_numpy 등
인덱싱, 슬라이싱, joining, mutating 연상 - transpose 등
수학 연산
- pointwise: abs, cos와 같이 텐서의 각 요소에 함수를 따로 적용해서 텐서를 새로 얻는 연산
- reduction: 텐서의 전체요소를 집계하는 연산. mean, std, norm 등
- comparison: equal, max
- spectral: 주파수 대역으로의 변환 및 연산. stft, hamming_window 등
- others: 벡터엔 cross, 행렬엔 trace
- BLAS & LAPACK: Basic Linear Algebra Subprograms을 따르는 함수.
랜덤 샘플링: randn, normal
직렬화(Serialization): load, save
병렬(Parallelism): 멀티코어 환경에서 멀티쓰레드. set_num_threads 등
추가로, 아래와 같이 언더스코어(_)가 붙은 텐서연산은 텐서인스턴스를 변환시킨다. (in-place operation)

3.7 Tensors: Scenic views of storage
텐서의 값들은 "torch.Storage"인스턴스에 의해 연속적인 메모리의 청크로 할당된다.
storage 하나는 float이나 int64 등의 타입을 갖는 뉴메릭 데이터의 1차원 배열이다.
텐서 인스턴스는 Storage 인스턴스의 view이다. offset과 per-dimension strides를 사용하여 storage을 인덱싱할 수 있다.
다수의 텐서 인스턴스는 같은 storage를 인덱스할 수 있다.


3.8 Tensor metadata: Size, offset, stride
size는 shape과 같은 의미로 각 차원의 크기를 의미한다. offset은 storage에서 해당 텐서의 시작 인덱스를 의미한다. stride는 차원마다 다음 요소를 참조하기 위해 storage에서 건너 뛰어야하는 간격을 의미한다.
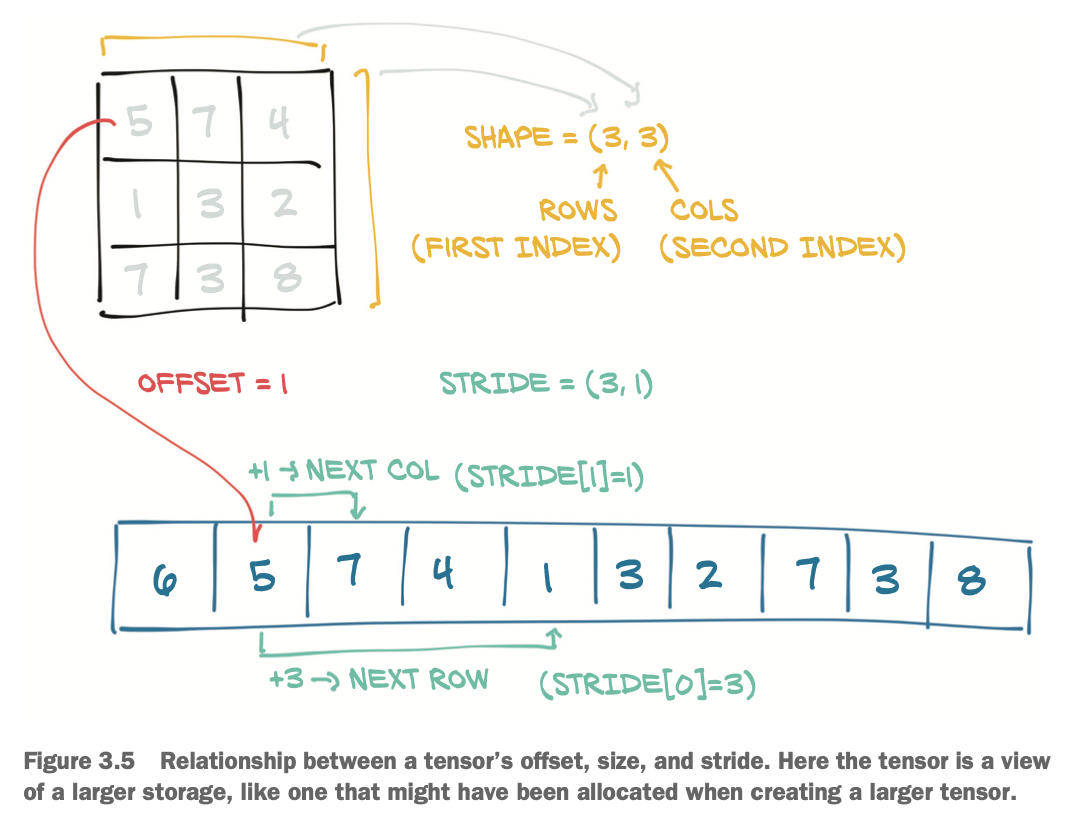


우측그림에서, 두 텐서(a,b)가 같은 storage를 보는 경우 a[0]=1 이런 식의 변경이 일어나면 storage에 변경이 일어나서 b도 변경된다. 아래그림과 같이 clone을 사용하여 문제를 해결할 수 있다.
3.8.2 Transposing without copying
storage의 변경없이 전치행렬을 구할 수 있다. stride의 순서만 바꾸면 된다. 고차원에 대해서도 마찬가지이다.
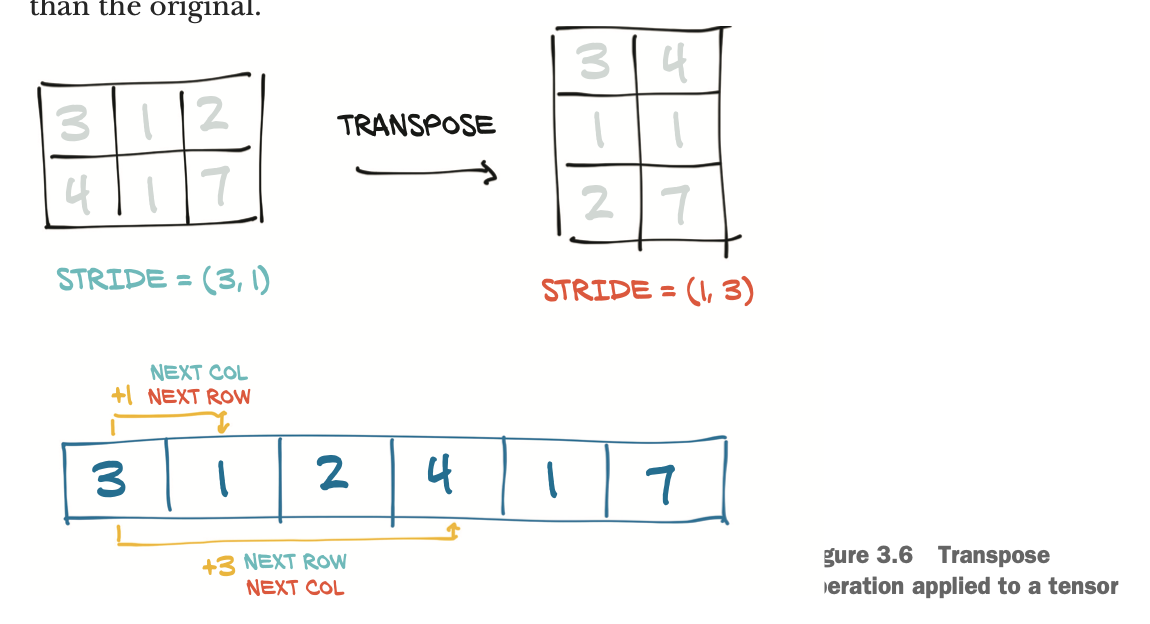

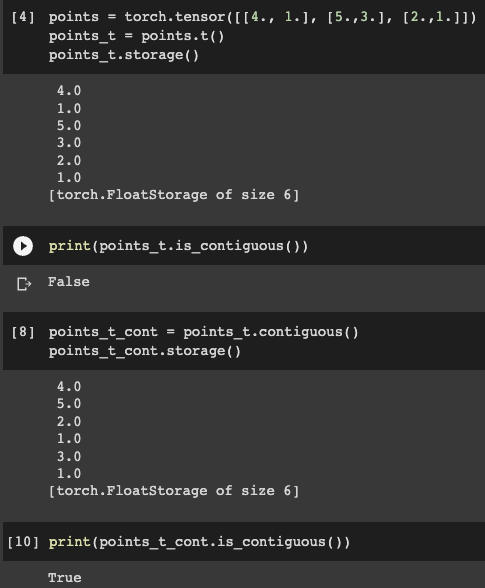
3.8.5 contiguous tensors
막 생성한 고차원 텐서에서 가장 우측 차원, 예를들어 shape (3,4,5)라면 5에 해당하는 차원은 "contiguous"라고 정의한다. contiguous텐서는 storage에 연속적으로 저장돼 있어서 효율적으로 순차방문 가능하다.
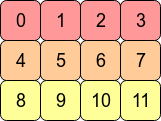


transpose연산을 하면 이 contiguous속성이 파괴된다. 연산의 효율성을 위해서 contiguous함수 등을 통해 메모리 재배치해야하는 경우가 있다. 'is_contiguous()'로 텐서가 contiguous한지 확인할 수 있다.
'view'와 같은 텐서 연산은 오직 contiguous 텐서에만 사용할 수 있다.
3.9 Moving tensors to the GPU
텐서엔 dtype외에도 device라는 요소가 있다. device는 텐서 데이터가 위치할 곳을 지정한다.


이렇게 device='cuda'를 하면 데이터를 일반적인 RAM이 아닌 GPU의 RAM에 올린다. 'cuda:0' 이런식으로 gpu코어가 여러개일 때 번호를 지정해주는 방식도 사용한다. points.cuda(), points.cuda(0), points_gpu.cpu() 같은 방식으로 변환도 가능하다.
한 번 GPU RAM에 올린 텐서는 연산 시 CPU로 뭔가 전달하지 않는다. 오직 GPU에서만 연산이 이뤄지는 셈.
3.10 NumPy interoperability
tensor와 numpy는 서로 쉽게 변환될 수 있다. 반환된 어레이는 텐서 스토리지와 동일한 기본 버퍼를 공유(buffer sharing strategy)한다. 즉, numpy 메서드는 데이터가 CPU RAM에 저장되어 있는 한 기본적으로 비용 없이 효과적으로 실행할 수 있다. 또한 NumPy 배열을 수정하면 원래 텐서가 변경된다. GPU에 텐서가 할당되면 PyTorch는 CPU에 할당된 NumPy 배열에 텐서의 내용을 복사한다.

텐서는 기본 타입이 32비트 실수, numpy는 64비트 실수이다. 넘파이를 텐서로 변환하면 보통 dtype이 float64니까 그때그때 필요하다면 바꿔줘야 한다.
3.11 Generalized tensors ar tensors, too
sparse tensor, quantized tensor등 다른 변형이 있음. 여태 소개한 일반적인 tensor는 dense tensor 또는 strided tensor라고 함. tensor API의 규격만 만족하면 모두 tensor인 셈. 아래 그림과 같이 텐서 연산 전 디스패처를 거치도록 해서 알맞은 연산을 할 수 있도록 함.

3.12 Serializing tensors
파이토치는 'pickl'을 사용해서 텐서 오브젝트를 직렬화하고 storage전용 직렬화 코드를 사용한다. 이 방법은 interoperable하지 않아서 파이토치 환경이 아니면 실행할 수 없다.
HDF5 형식으로 직렬화하여 저장한다면 다른 환경에서도 호환 가능하다.
'ML&DATA > 책 & 강의' 카테고리의 다른 글
| NLP with Transformers - Ch1 (0) | 2022.03.28 |
|---|---|
| Deep Learning with PyTorch - Ch6 (0) | 2022.03.28 |
| Deep Learning with PyTorch - Ch5 (0) | 2022.03.26 |

