Ch6. Using a neural network to fit the data
6.1 Artificial neurons
neural network:
- 간단한 함수의 조합으로 복잡한 함수를 표현할 수 있는 수학적 요소
- neuron: neural network의 기초 블록(layer). input -> linear transformation -> activation -> output 형태.
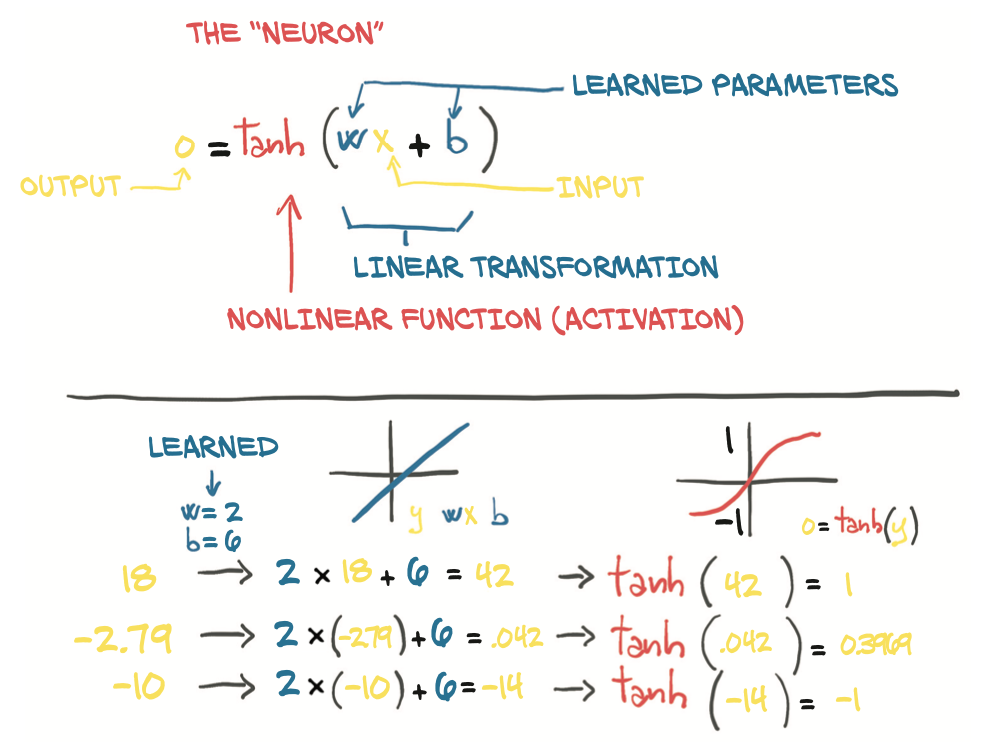
6.1.2 Understanding the error function
에러함수에서 최적지점이 하나만 존재하는게 아니라 지역최적, 전역최적점이 존재한다는 말인듯
6.1.3 All we need is activation
활성함수의 2가지 역할
- 모델의 내부에선, output함수가 다른 값들에 대해 다른 기울기를 갖게 하도록 함(선형함수로는 불가능).
- 네트워크의 마지막 레이어에선, output이 특정 범위에 들어오도록 함
아래와 같은 활성함수들이 있는데, ReLU가 일반적으로 가장 좋은 성능을 냄.
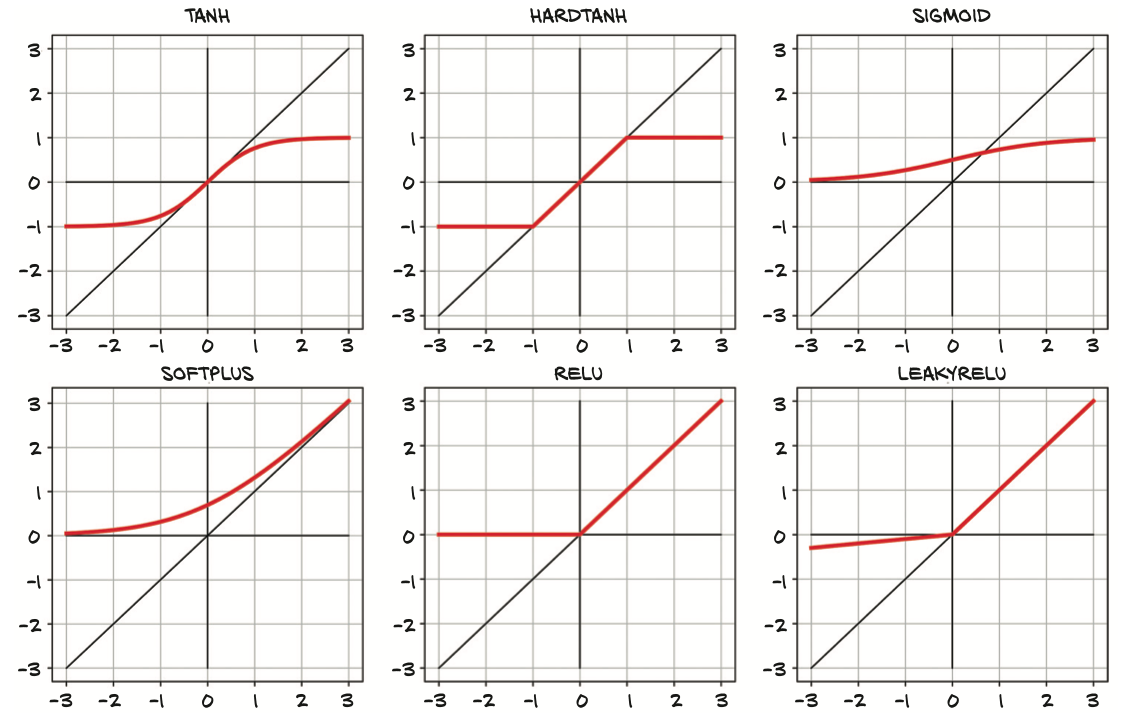
활성함수는
- 비선형: 전체 네트워크가 더 복잡한 함수를 나타낼 수 있다.
- 미분가능: gradient가 역전파될 수 있도록 함
- input의 중요한 변화가 output에 반영될 수 있도록 함
- input의 중요하지 않은 변화가 output에 반영되지 않도록 함
- 하한이 존재함.
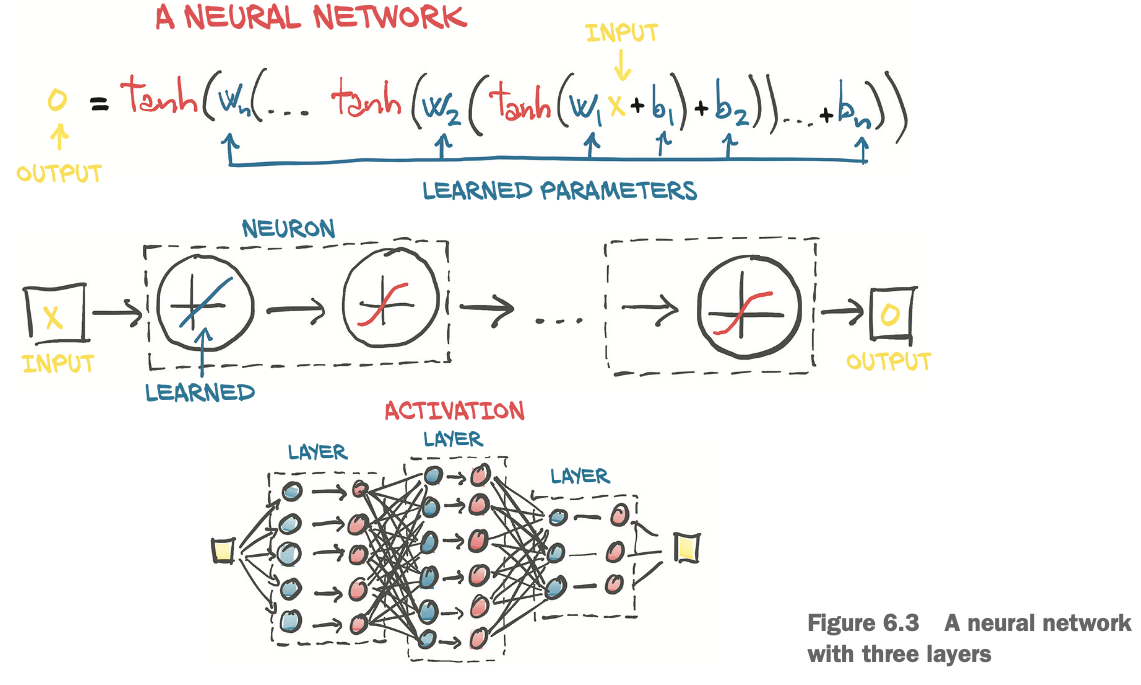
선형변환 -> 미분가능한 활성함수(뉴런)를 쌓은 모델은 비선형 데이터를 효과적으로 근사해낼 수 있다.
네 개의 뉴런만으로 다음 그림과 같이 다양한 비선형 결과를 낼 수 있다.

6.2 The PyTorch nn module
torch.nn에 모듈(레이어) 정의.
list나 dict에 모듈을 넣지 않도록 유의해야 함. nn.ModuleList, nn.ModuleDict
model의 forward 직접호출하지 않고, __call__메소드를 통해서 호출해야함. __call__메소드엔 forward호출 뿐 아니라 여러 다양한 훅들을 호출함.
브로드캐스팅 덕분에 쉽게 배치작업 가능. 아래 코드 참고
seq_model = nn.Sequential(OrderedDict([
('hidden_linear', nn.Linear(1, 8)), #(B, Ninput)
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(8, 1))
]))
for name, param in seq_model.named_parameters():
print(name, param.shape)
#hidden_linear.weight torch.Size([8, 1])
#hidden_linear.bias torch.Size([8])
#output_linear.weight torch.Size([1, 8])
#output_linear.bias torch.Size([1])
optimizer = optim.SGD(seq_model.parameters(), lr=1e-3)
training_loop(
n_epochs = 5000,
optimizer = optimizer,
model = seq_model,
loss_fn = nn.MSELoss(),
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val)
def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val, t_c_train, t_c_val):
for epoch in range(1, n_epochs + 1):
t_p_train = model(t_u_train) #model에 param 반영돼 있음.
loss_train = loss_fn(t_p_train, t_c_train)
t_p_val = model(t_u_val)
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
'ML&DATA > 책 & 강의' 카테고리의 다른 글
| NLP with Transformers - Ch1 (0) | 2022.03.28 |
|---|---|
| Deep Learning with PyTorch - Ch5 (0) | 2022.03.26 |
| Deep Learning with PyTorch - ~Ch3 (0) | 2022.03.16 |

