<learning rate>
ㅁ
learning rate를 너무 크게 하면 loss가 일정 수준에서 더 떨어지지 않고, 너무 작게하면 가중치 matrix를 만드는 데 시간이 너무 많이 걸린다. 따라서 적절한 learning rate를 정해줘야 한다.
ㅁ
learning rate decay : 일정 epochs마다 learning rate를 줄여서 loss를 더더욱 낮추는 기법
exponential decay, 1/t decay 등 다양하다.
tf.compat.v1.train.exponential_decay()...
텐서1에서나 사용했던 방법인거 같기도 하다
<data preprocessing>
ㅁ
standardization, normalization 등으로 평균에 지나치게 벗어난 값들을 유의미한 값으로 바꿔준다.


(normalization 예제)
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
def normalization(data):
numerator = data - np.min(data,0)
denominator = np.max(data, 0) - np.min(data,0)
return numerator / denominator
xy = np.array([[828.659973, 833.450012, 908100, 828.349976, 831.659973],
[823.02002, 828.070007, 1828100, 821.655029, 828.070007],
[819.929993, 824.400024, 1438100, 818.97998, 824.159973],
[816, 820.958984, 1008100, 815.48999, 819.23999],
[819.359985, 823, 1188100, 818.469971, 818.97998],
[819, 823, 1198100, 816, 820.450012],
[811.700012, 815.25, 1098100, 809.780029, 813.669983],
[809.51001, 816.659973, 1398100, 804.539978, 809.559998]])
x_train = xy[:,0:-1]
y_train = xy[:,[-1]]
plt.plot(x_train, 'ro')
plt.plot(y_train)
plt.show()xy 5열 중 4열이 feature고 마지막 1열이 label인 데이터.

plt로 찍어보면 위와 같다.
xy = normalization(xy)
x_train = xy[:,0:-1]
y_train = xy[:,[-1]]
plt.plot(x_train, 'ro')
plt.plot(y_train)
plt.show()정규화 후에 찍어보면 아래와 같다

ㅁ
noisy data : 필요없는 데이터. 노이즈라고도 하며 이를 제거하는 과정이 필요하다.
ex)얼굴인식 시 얼굴 외 구역
<overfitting>
ㅁ
feature가 너무 많아지는 경우 train data에 대해선 잘 동작하지만 새로운 입력에 대한 라벨을 잘 예측하지 못하는 상태이다.
더 많은 training data로 더 학습시키거나 feature의 수를 줄이는 방법으로 accuracy를 올릴 수 있다.
feature의 수를 줄이는 것은 사이킷 런의 PCA어쩌구를 사용한다.
ㅁ
underfitting의 경우 더 많은 feature를 사용하여 해결할 수 있다.
ㅁ
regularization : 가중치벡터의 제곱 평균에 상수(람다)값을 곱한 것을 기존 비용함수에 더해서 비용함수를 구성한다.
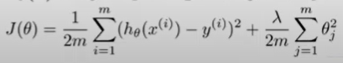
L2_loss = tf.nn.l2_loss(w)
ㅁ
이외에 dropout이나 batch normalization은 neural network 학습 이후에 설명한다고 함.
<data set>
ㅁ
training set과 validation(test) set을 class마다 균등하게 구성해야 함.
<learning>
ㅁ online vs batch(offline)
online learning은 데이터가 지속적으로 유입이됨. 모델이 유동적이고 인프라 필요. real-time 처리해야하므로 속도 중요
batch learning은 정적인 데이터로 학습. 모델은 어느 상태로 수렴하며 정확성이 중요하다.
ㅁ fine tuning vs feature extraction
백인의 얼굴을 식별하는 모델을 이미 만들었는데 황인과 흑인의 얼굴도 식별하고자 하는 상황.
fine tuning : 더 많은 test data로 weight들을 미세하게 조정하면서 모델을 수정
feature extraction : 기존의 모델을 수정하지 않고 추가해서 수행
추상적으로 설명하고 넘어가심. 어려운 개념인듯
ㅁ efficient model
모델의 수행시간도 중요하다.
'ML&DATA > 모두를 위한 딥러닝' 카테고리의 다른 글
| 실습 (0) | 2020.07.13 |
|---|---|
| multinomial classification (0) | 2020.07.12 |
| binary classification (0) | 2020.07.10 |
| simple linear regression (단순 선형 회귀) (0) | 2020.07.08 |
| 용어/개념 (0) | 2020.07.08 |


