www.youtube.com/watch?v=6omvN1nuZMc&list=PLJN246lAkhQjX3LOdLVnfdFaCbGouEBeb&index=13
박해선 교수님의 유튜브 강의로 공부했음을 밝힙니다.
다항회귀
비선형 데이터를 학습하는 데 선형 모델을 사용할 수 있다. 각 특성의 거듭제곱을 새로운 특성으로 추가하고, 이 확장된 특성을 포함한 데이터셋에 선형 모델을 훈련시키는 것이다. 이런 기법을 다항 회귀(polynomial regression)라고 한다.
<실제 모듈 사용>

1. polynomialfeature로 특성 확장 후 선형 모델 학습
직선은 이 데이터에 잘 맞지 않을 것이므로 우선 사이킷런의 PolynomialFeatures를 사용해 훈련 데이터를 확장한다
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias = False)
X_poly = poly_features.fit_transform(X)
X[0] #array([-0.75275929])
X_poly[0] #array([-0.75275929, 0.56664654])
# include_bias = True, 편향을 위한 특성 1
#linearregression 모델이 model.intercept_, model.coef_ 알아서 구해줌
# 편향을 위한 특성 x_0 없이 사용
확장된 데이터로 선형모델 학습한다.
lin_reg = LinearRegression()
lin_reg.fit(X_poly,y)
lin_reg.intercept_, lin_reg.coef_
#(array([1.78134581]), array([[0.93366893, 0.56456263]]))
실제 함수가 $y = 0.5x_1^{2} + 1.0x_1+2.0+noise$이고 예측된 모델은 $\hat{y} = 0.56x_1^{2} + 0.93x_1+1.78$이다.
2. 릿지 회귀
2.1 Ridge클래스사용
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver = 'cholesky', random_state=42)
ridge_reg.fit(X,y)
ridge_reg.predict([[1.5]])
#array([[1.55071465]])
2.2 SGDRegressor 사용
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X, y.ravel())
sgd_reg.predict([[1.5]])
#array([1.47012588])
3. 라쏘 회귀
3.1 Lasso클래스사용
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X,y)
lasso_reg.predict([[1.5]])
#array([1.53788174])
3.2 SGDRegressor사용
sgd_reg = SGDRegressor(penalty='l1')
sgd_reg.fit(X, y.ravel())
sgd_reg.predict([[1.5]])
4. 엘라스틱넷
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X,y)
elastic_net.predict([[1.5]])
#array([1.54333232])
5. 조기종료
early_stopping옵션을 True로 주고, n_iter_no_change(기본값5) 동안 성능이 좋아지지 않는다면 조기종료한다.
sgd_reg = SGDRegressor(penalty=None, learning_rate = 'constant', eta0 = 0.0005, random_state=42,
early_stopping=True)
sgd_reg.fit(X_train_poly_scaled, y_train)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
mean_squared_error(y_val, y_val_predict), sgd_reg.n_iter_<학습 곡선>

300차, 2차, 1차 다항회귀모델을 그래프로 나타낸 것이다. 300차 모델은 훈련 데이터에 과대적합 됐다. 반면 1차 모델은 훈련 데이터에 과소적합 됐다.
모델이 데이터에 과대/과소 적합됐는지 파악하는 한가지 방법은 학습곡선을 살펴보는 것이다.
학습곡선은 훈련세트와 검증세트의 모델 성능(ex, RMSE)을 y축으로하고 훈련세트의 크기를 x축으로 한 함수의 그래프다.
polynomialfeature로 특성 확장을 하기 전의 날것의 데이터 X(직선)를 linearRegression모델로 학습시켰을 때 학습곡선은 다음과 같다.
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
#model과 데이터X, 라벨 y의 학습곡선을 그려주는 함수
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X,y,test_size=0.2, random_state=10)
train_errors, val_errors = [], []
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
plt.plot(np.sqrt(train_errors), 'r-+', linewidth=2, label = 'train')
plt.plot(np.sqrt(val_errors), 'b-', linewidth=3, label = 'val')
plt.legend(loc='upper right', fontsize=14)
plt.xlabel('Training set size', fontsize=14)
plt.ylabel('RMSE', fontsize=14)
lin_reg = LinearRegression()
plt.axis([0,80,0,3])
plot_learning_curves(lin_reg,X,y)
10차 다항회귀의 학습곡선을 그리면 다음과 같다.
polynomial_regression = Pipeline([
('poly_features', PolynomialFeatures(degree=10, include_bias=False)),
('lin_reg', LinearRegression()),
])
plt.axis([0,80,0,3])
plot_learning_curves(polynomial_regression, X,y)
2차 다항회귀의 학습곡선은 다음과 같다.
polynomial_regression = Pipeline([
('poly_features', PolynomialFeatures(degree=2, include_bias=False)),
('lin_reg', LinearRegression()),
])
plt.axis([0,80,0,3])
plot_learning_curves(polynomial_regression, X,y)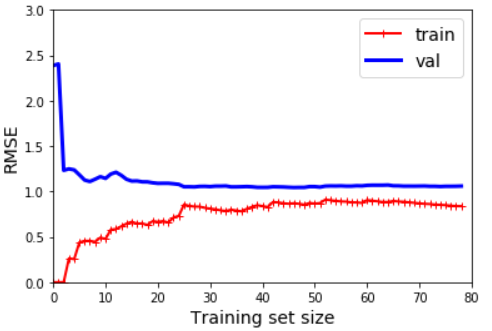
과소적합된 모델 :
- train, val 곡선 사이의 공간이 매우 작다.
- 성능(RMSE)이 비교적 떨어진다.
과대적합된 모델:
- train, val 곡선 사이의 공간이 넓다. (훈련데이터에서의 성능이 검증데이터에서보다 훨씬 좋다는 뜻)
- 성능(RMSE)가 비교적 좋다
<편향/분산 트레이드오프>
모델의 일반화 오차는 편향 + 분산 + 줄일수없는 오차의 합으로 나타낼 수 있다.
1. 편향
잘못된 가정으로 인한 것. 예를들어 데이터는 2차인데 선형으로 가정하는 경우. 편향이 큰 모델은 훈련 데이터엑 과소적합되기 쉽다.
2. 분산
훈련 데이터에 있는 작은 변동에 모델이 과도하게 민감하기 때문에 나타남. 자유도가 높은 모델(ex, 고차 다항 회귀 모델)은 높은 분산을 가지기 쉬워 훈련 데이터에 과대적합 되는 경향이 있다.
3. 줄일 수 없는 오차
데이터 자체에 있는 잡음 때문에 발생. 데이터에서 잡음을 제거하는 것이 유일한 해결책
트레이드오프
ㅁ 모델의 복잡도가 커지면 분산이 늘어나고 편향이 줄어든다.
ㅁ 모델의 복잡도가 줄어들면 분산이 줄어들고 편향이 늘어난다.
<규제가 있는 선형 회귀 모델>
과대적합을 감소시키기 위한 한가지 방법으로 모델을 규제함
릿지, 라쏘, 엘라스틱넷은 모델의 가중치를 제한함으로써 규제를 가한다. 규제항은 훈련하는 동안만 사용한다. 예측할땐 사용하는 것 아님.
(일반적으로 훈련시 쓰는 비용함수와 테스트에서 사용되는 성능 지표는 다르다.)
결론부터 말하자면 릿지 회귀를 가장 많이 쓴다. 하지만 쓰이는 특성이 적을 땐 엘라스틱 넷이 낫다.
반복적인 학습 알고리즘을 규제하는 방법으론 조기종료가 있다. 에포크가 어느 수준 이상 늘어나면 과대적합되는 문제를 해결해준다. 매우 효과적이고 간단한 방법으로 제프리 힌턴이 beautiful free lunch라고 불렀다고 함.
1. 릿지 회귀
티호노프 규제라고도 함.
규제항으로 하이퍼 파라미터 $\alpha$를 곱한 $l_2$노름을 사용한다.

$w$를 특성의 가중치 벡터($\theta_1$에서 $\theta_n$까지)라고 정의하면 규제항은 가중치벡터 $w$의 $l_2$ 노름이다.
경사 하강법에 적용하려면 MSE 그래디언트 벡터에 $\alpha w$를 더하면 된다.
위에서 썼듯 sklearn.linear_model의 Ridge 모듈을 사용한다.
내부적으로 linearRegression과 비슷하게 'cholesky'가 발견한 행렬 분해를 사용하여 정규방정식을 계산한다.
(릿지회귀모델은 항상 역행렬 존재)
SGDRegressor를 사용할 땐 penalty에 'l2'를 명시해주면 된다.
2. 라쏘 회귀
규제항으로 하이퍼 파라미터 $\alpha$를 곱한 $l_1$노름을 사용한다.

라쏘 회귀는 덜 중요한 특성의 가중치를 0에 수렴시켜 그 가중치를 제거하려고 한다.
다시말해서 라쏘 회귀는 자동으로 특성 선택을 하고 희소 모델을 만든다.
3. 엘라스틱넷
elastic net 은 릿지회귀와 라쏘회귀를 절충한 모델이다.

참고로 r=1이면 라쏘회귀와 100% 같다. r=0일땐 릿지회귀와 내부 구현이 다르다.
4. 조기종료

반복 학습시 에포크가 늘어남에 따라서 훈련셋에 과대적합되는 문제가 있다. 단순히 매 에포크마다 성능을 평가해서 최대 성능을 내는 모델을 유지하기만 하면 된다. 모델을 유지하기 위해 sklearn.base의 clone을 사용한다.
from sklearn.base import clone
poly_scaler = Pipeline([
('poly_features', PolynomialFeatures(degree=90, include_bias=False)),
('std_scaler', StandardScaler())
])
#fit_transform -> fit_transform
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
#transform_-> transform
X_val_poly_scaled = poly_scaler.transform(X_val)
sgd_reg = SGDRegressor(max_iter=1, tol=-np.infty, warm_start=True,
penalty=None, learning_rate="constant", eta0=0.0005, random_state=42)
minimum_val_error = float("inf")
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val, y_val_predict)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = clone(sgd_reg)
early_stopping, n_iter_no_change옵션을 설정하는 방법도 있다.
'ML&DATA > 핸즈온 머신러닝' 카테고리의 다른 글
| 4 - 정리, 연습문제 (0) | 2020.09.18 |
|---|---|
| 4 - 로지스틱 회귀, 소프트맥스 회귀 (0) | 2020.09.15 |
| 4 - 선형회귀 (경사하강법) (0) | 2020.09.04 |
| 4 - 선형 회귀 (정규방정식) (0) | 2020.09.04 |
| 3 - 다중 레이블 분류, 다중 출력 분류 (2) | 2020.08.27 |



