책에서 소개한 형식과 약간 다르다. 엑셀/탭으로 구분된 txt파일
2016년도까지의 데이터 기준. 인구수는 2020년 기준이다.
구별 인구수가 2016년도와 2020년도가 비슷하다고 가정하고 진행하겠음.
ㅁ 서울시 구별 CCTV 개수 현황을 분석하여 어떤 구에 더 CCTV를 설치해야 하는지 결정.
1) 구별 CCTV 개수와 가장 큰 상관이 있어 보이는 특성 찾기.
2) 해당 특성과 CCTV 개수가 관련이있는지 시각화.
3) 관련이 있다면, CCTV 개수가 그 경향보다 많이설치됐는지 적게 설치됐는지 판단, 시각화
<데이터 읽어오기>
우선 구별/연도별 CCTV 현황을 읽어서 CCTV_Seoul DataFrame객체에 넣어둔다.
소계는 전체 CCTV수를 의미한다.

'기관명' 컬럼이름을 '구별'로 바꿔준다
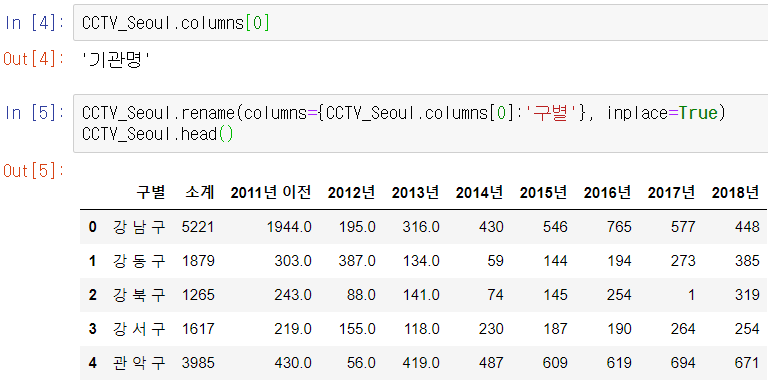
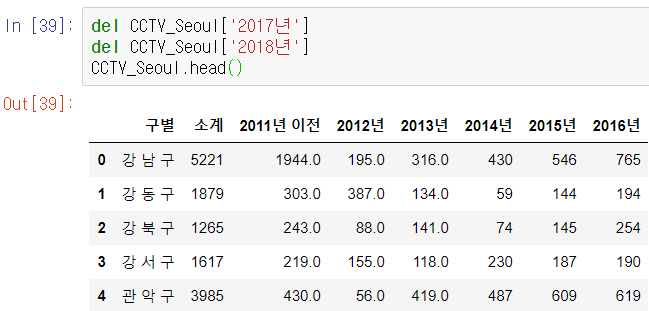
책에서 2016년도까지의 현황을 살펴봤으니 여기서도 그렇게 하기 위해 컬럼을 잘라준다.
'소계'를 다시 계산해준다.
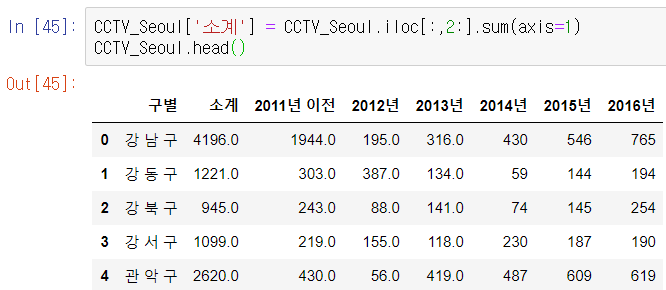
2011년이전~2013년까지를 묶어준다.

이제 구별 현재 인구를 읽어오자.
현재 구별, 분류별(총인구/한국인/외국인/고령자) 서울시 인구를 읽어 pop_Seoul에 넣어준다.
이떄, 남자/여자는 따로 구분하지 않으므로 파일을 잘 봐서 usecols옵션으로 적절한 컬럼을 선택한다.

컬럼명을 다시 붙여준다.
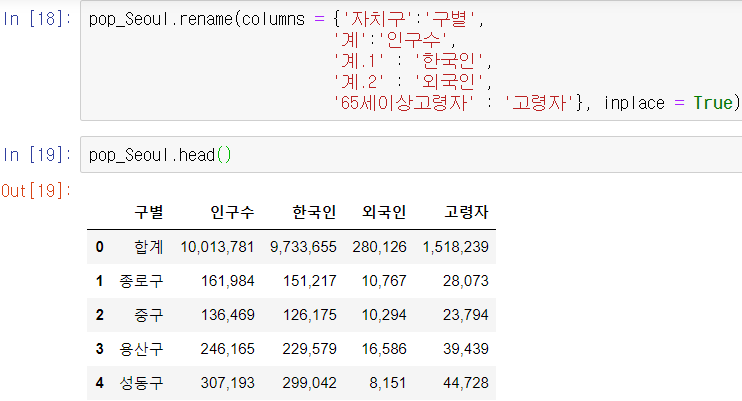
책에 있는 데이터와 수치 차이가 심하다. 동대문구와 중랑구에 누락된 데이터가 있다.
<현황 파악하기>
CCTV개수가 많은 구와 적은 구를 확인해보자.

CCTV의 전체 개수가 가장 적은 구는 '도봉구', '광진구', '중구', '금천구', '강북구'이다.
CCTV의 전체 개수가 가장 많은 구는 '강남구', '관악구', '은평구', '구로구', '서초구'이다.
(강남구의 경우 내 자료는 4196개인데 책의 자료는 2780이다. 2013년 이전의 cctv대수의 차이가 매우 크다. 서초구의 경우는 차이가 크게 나지 않는다.)
DataFrame에 CCTV의 최근 증가율 컬럼을 넣어보자
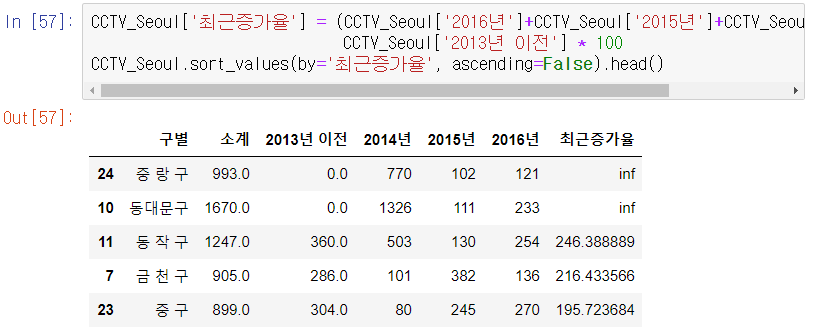
역시 동대문구와 중랑구의 누락된 데이터가 문제다. 대충 2014년 데이터가 2014년이전 데이터를 의미하는 것 같으니, 중랑구, 동대문구의 2,3번 컬럼을 swap해주었다.
CCTV_Seoul.iloc[24,2], CCTV_Seoul.iloc[24,3] = CCTV_Seoul.iloc[24,3], CCTV_Seoul.iloc[24,2]
CCTV_Seoul.iloc[10,2], CCTV_Seoul.iloc[10,3] = CCTV_Seoul.iloc[10,3], CCTV_Seoul.iloc[10,2]
그리고 다시 돌려보면

최근 3년간 CCTV가 가장 많이 증가한 구는 '동작구','금천구','중구','영등포구','관악구' 이다. (책과 완전히 다르다.)
이제 서울시 인구현황을 살펴보자

우린 구별 인구수가 필요한거지 합계 인구수는 필요없으니 drop명령어로 0번 행을 지운다.
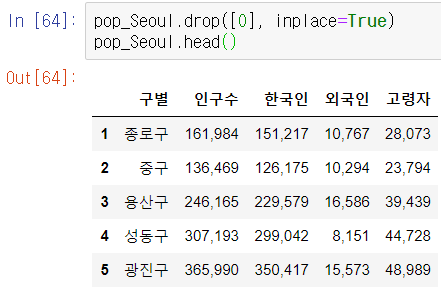
널값이 포함된 행이 있는지 확인해준다.

'외국인비율', '고령자비율' 컬럼을 추가한다.
추가하기전에 1000단위로 찍힌 ,를 없애준다. 다음부턴 read_csv하면서 thousands옵션으로 제거하자

이제 '외국인비율', '고령자비율' 컬럼을 추가한다.

인구수 탑5
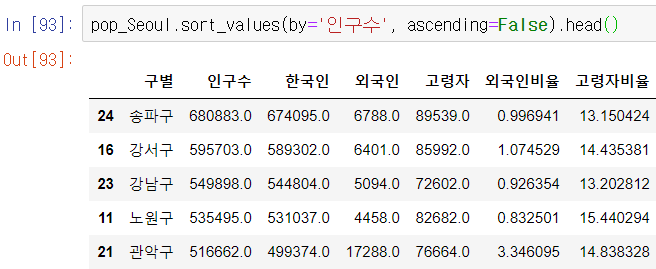
외국인, 외국인비율 탑5

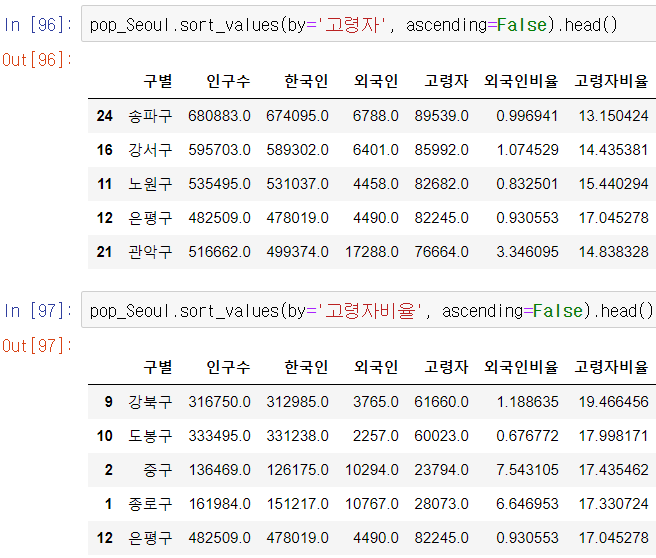
65세이상 고령자, 고령자비율 탑5
<데이터 합쳐서 보기>
우리가 원하는 것은 구별 cctv개수와 인구수의 상관관계이다.
따라서 두 DataFrame을 병합해서 확인해야한다. '구별'을 기준으로 merge하면 다음과 같다
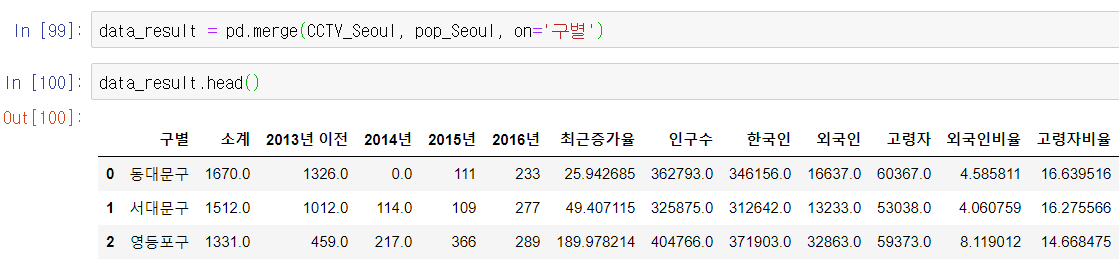
지금보니 CCTV_Seoul에 구별이름이 '강 남 구' 이딴식으로 들어가있다. 아래와같이 수정하자
CCTV_Seoul['구별'] = CCTV_Seoul['구별'].str.replace(' ', '')
다시 머지하면

이제 연도별 cctv개수는 필요없으니 모두 삭제해준다.

인덱스를 구 이름으로 설정한다.

다양한 특성들(고령자비율, 외국인비율, 인구수) 중에서 어떤 데이터와 CCTV대수를 비교할지 결정해야 하는데, 어떤 특성과 cctv개수의 상관계수의 절대값이 0.7이상이면 뚜렷한 상관관계, 0.3이상이면 보통 상관관계, 0.1이상이면 약한 상관관계, 그 이하면 거의 무시하면 된다고 한다.
그럼 다수의 특성 중 상관계수의 절대값이 가장 큰 특성을 찾아보자.
상관계수는 numpy의 corrcoef명령으로 알아볼 수 있다. 결과는 행렬로 나타난다.

CCTV개수와 고령자비율은 중간 음의 상관관계이고, 외극인비율은 큰 의미가 없다.
인구수와는 상관계수가 0.38로 중간 양의 상관관계가 있다고 볼 수 있고 고령자비율과의 상관관계보다 절대값이 크다.
seaborn의 pairplot으로 모든 변수 간 산포도를 뽑으면 다음과 같다.
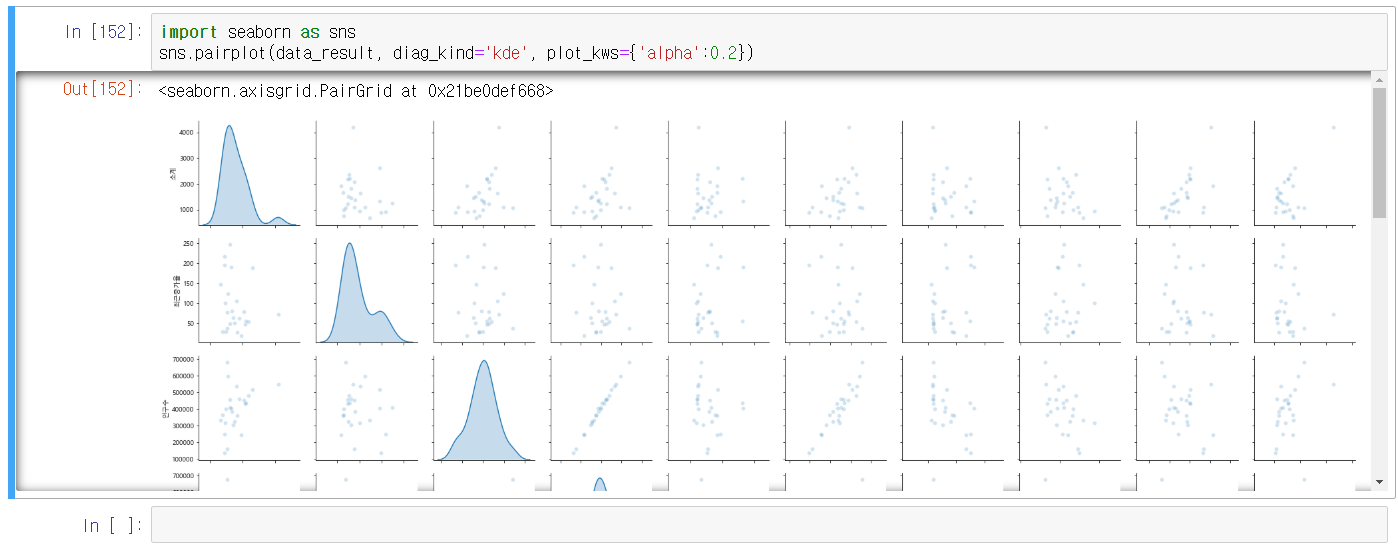
상관관계를 생각하기 힘들 때 통찰을 얻을 수 있을 것 같다. 10*10을 그리는데 30-40초 걸린다.
그러면 CCTV와 인구수의 관계를 조금 더 들여다 보자

위와같이 cctv가 많이설치된 구와, 인구수가 많은 구를 시각적으로 비교하면 좋을 것 같다.
matplotlib에 한글폰트를 추가하고 data_result의 '소계'를 막대그래프로 시각화해보자
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus']=False
path = 'C:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)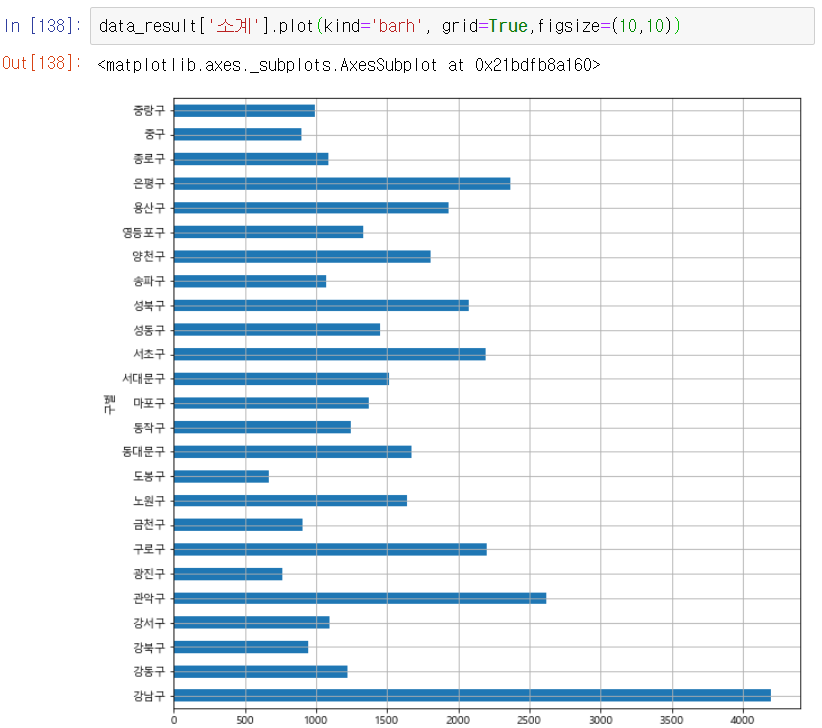
수평 막대그래프는 정렬돼 있는 것이 더 의미있다.

인구 대비 'CCTV비율' 컬럼을 만들어서 마찬가지로 막대그래프를 그리면 다음과 같다.

송파구는 인구수대비 cctv비율이 많이 낮다.
이제 인구수를 x축으로, cctv개수를 y축으로 한 산포도를 그려보자. s는 마커(점)의 크기다.

이제 이 데이터를 대표하는 함수를 그려보자. (여기선 직선)
np.polyfit에 x축,y축데이터,대표함수의 차수를 넣어 쉽게 선을 만들 수 있다.
(차수가 1인 경우 기울기와 bias가 나온다)
polyfit으로 만든 함수(직선)로 x축,y축 데이터를 얻어야 하는데, x축 데이터는 np.linspace(예제에선 10000~70000를 100구간으로 나눈 숫자의 배열)로 만들고, y축 데이터는 poly1d(fp1의 가중치와 bias로 대표함수를 만듬)에 x데이터를 넣은 것으로 만들 수 있다.

여기서 두가지 장치를 넣고자 한다.
ㅁ 대표함수에서 많이 떨어진 특이값 상위 10개 구를 나타내는 마커(점)에 구 이름을 띄우는 것
텍스트는 점의 우하단에 띄울 것.
ㅁ 대표함수에서 너무 멀리 떨어진 마커일수록 눈에 띄는 색으로 칠하는것
그래서 오차를 계산(단순히 예측값-결과값)하여 오차컬럼을 추가해서 오차 기준으로 내림차순 정렬하면 다음과 같다.

이제 텍스트와 colormap을 입히자. plt.scatter의 c옵션은 색깔이다.
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'], data_result['소계'],
c = data_result['오차'], s=50)
plt.plot(fx,f1(fx),lw=3,color='g')
df_sort = data_result.sort_values(by='오차', ascending=False)
for i in range(10):
plt.text(df_sort['인구수'][i]*1.02, df_sort['소계'][i]*0.98,
df_sort.index[i], fontsize=15)
plt.xlabel('인구수')
plt.ylabel('CCTV개수')
plt.colorbar()
plt.grid()
인구수가 증가할수록 CCTV의 개수가 많아지는 경향이 있다.
인구수가 증가할수록 CCTV개수가 많아져야 하는 것이 정당하다면,
강남,관악,은평,구로,용산은 일반적인 경향보다 CCTV가 더 많이 설치됐음.
도봉,광진,중랑,강서,송파는 일반적인 경향보다 CCTV가 더 적게 설치됐으므로 공평을 위해 증설이 필요하다.
'ML&DATA > 파이썬으로 데이터 주무르기' 카테고리의 다른 글
| 셀프주유소는 정말 저렴할까 (0) | 2020.08.14 |
|---|---|
| 시계열 데이터 다루기 (0) | 2020.08.11 |
| 영화별 날짜 변화에 따른 평점 변화 확인하기 (0) | 2020.08.11 |
| 네이버 영화 홈페이지에서 영화의 평점 변화 정리하기 (0) | 2020.08.11 |
| 시카고 샌드위치 맛집 분석 (0) | 2020.08.08 |



