<목표>
https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&tg=0&date=20200501
위 사이트에서 2020년 5월 1일로부터 100일간의 영화별 기간별 평점을 정리한다.
<데이터가져오기>
https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&tg=0&date=20200501
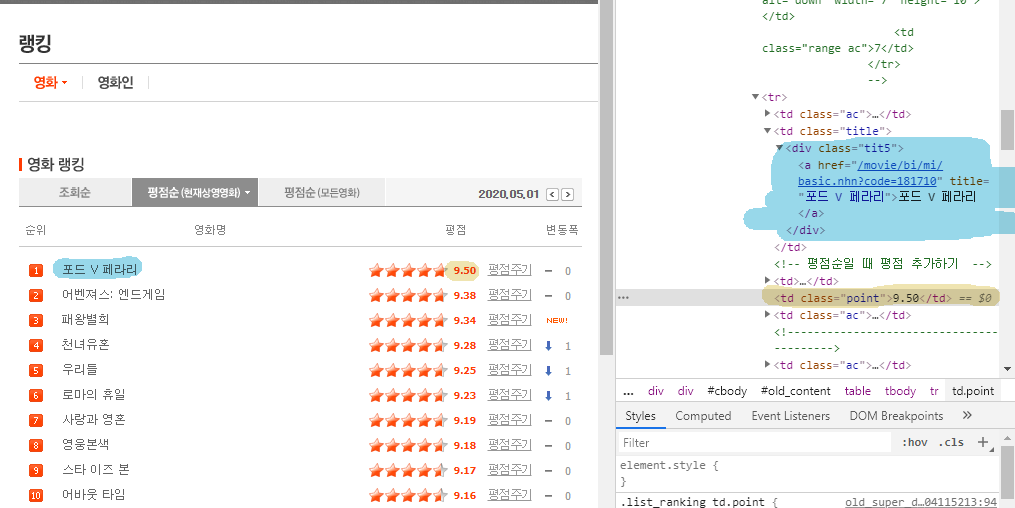
링크의 홈페이지는 date={date}로 날짜별로 구분되어 있다.
영화제목은 tit5 클래스 div태그의 내부의 a태그 안에 텍스트로 들어있다
평점은 point클래스 td태그에 텍스트로 들어있다.
홈페이지 주소를 urllib모듈의 urlopen으로 html문서를 page에 넣은 후에 beautifulsoup 객체에 html.parser와 함께 넣어준다.

시카고 샌드위치 때와 같이 Beautifulsoup객체의 find_all로 태그와 클래스를 검색해줄 수 있다.

판다스 시계열 객체를 2020년 5월 1일부터 100일짜리를 만들어준다.
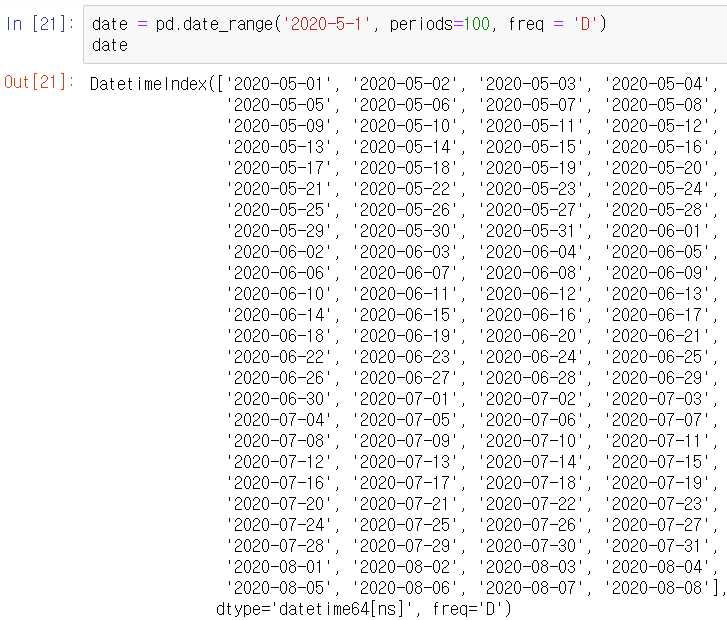
이제 이 날짜마다의 해당하는 영화의 이름과 그때의 평점을 DataFrame에 정리해보자.
일단 각각의 날짜,영화제목,평점을 리스트로 받아둔 후에 DataFrame에 넣는 식으로 짠다.

point의 형식은 string이므로 실수타입으로 형변환 해준다.

여기까지 날짜, 영화, 평점을 DataFrame에 가져오는 것은 마쳤다.
만약 100일간 평점 합이 큰 순서대로 영화 이름을 보고싶다면 pivot table을 활용하면 된다.
(상영 기간이 모두 다르므로 의미있는 데이터는 아니다.)

DataFrame의 query메서드로 어떤 영화만 선택할 수도 있다.

'ML&DATA > 파이썬으로 데이터 주무르기' 카테고리의 다른 글
| 셀프주유소는 정말 저렴할까 (0) | 2020.08.14 |
|---|---|
| 시계열 데이터 다루기 (0) | 2020.08.11 |
| 영화별 날짜 변화에 따른 평점 변화 확인하기 (0) | 2020.08.11 |
| 시카고 샌드위치 맛집 분석 (0) | 2020.08.08 |
| 서울시 구별 CCTV 현황 분석 (0) | 2020.07.29 |



