시간의 흐름에 따라 변화하는 추이가 있는 데이터를 다루는 것을 시계열 분석이라고 한다.
이는 어렵고 복잡한 작업이다. 원 데이터의 안정성(stationary)를 판정하고, 안정한 형태로 변환하고, 예측모델을 선정하고 검증하는 과정이 통계학의 깊은 지식을 요구한다.
이 단원에선 어렵고 빡빡한 데이터 예측이 아닌 가볍고 쉬운 케이스만 예를 들어 준다.
<numpy의 polyfit으로 regression분석하기>
ㅁ목표
저자의 블로그의 트래픽의 경향을 분석한다.
ㅁ본문
모듈 포함시키고 폰트 설정
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import pandas_datareader.data as web
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from fbprophet import Prophet
from datetime import datetime
path = "c:/Windows/Fonts/malgun.ttf"
import platform
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
plt.rcParams['axes.unicode_minus'] = False
저자 블로그의 날짜별 트래픽(hit)를 DataFrame에 불러온다.
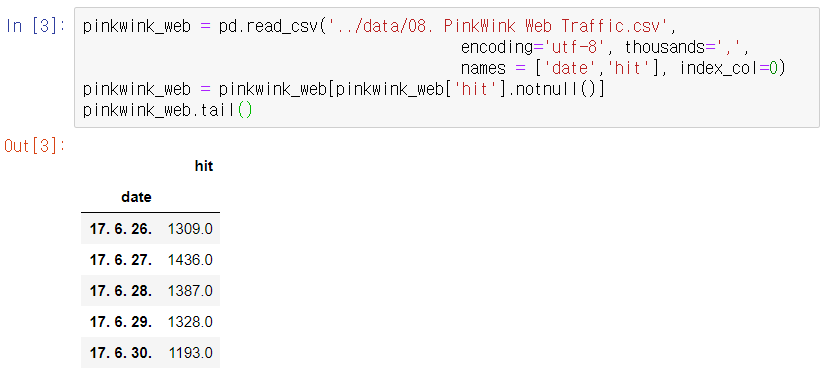

위와 같이 단순히 트래픽을 눈으로만 봐선 주기성을 파악하기 힘들다. 위 그래프를 대표할 간단한 함수를 찾아보자. 그 함수는 직선,다항식,곡선일 수 있다. 이렇게 현재 데이터를 간단한 모델로 표현하는 것을 regression이라고 한다. 모델을 1차, 2차, 3차, 15차 다항식으로 표현하고 그 결과를 확인해보자.
시간축(time)을 만들고 웹 트래픽의 자료를 traffic 변수에 저장한다.
time = np.arange(len(pinkwink_web))
traffic = pinkwink_web['hit'].values
fx = np.linspace(0,time[-1],1000)
에러함수를 정의한다.
def error(f,x,y):
return np.sqrt(np.mean((f(x)-y)**2))
time을 x축, traffic을 y축, 차수를 정해서
polyfit으로 가중치 리스트를 만들고, poly1d로 그 리스트를 받아서 함수를 만든다.

이걸 그래프로 확인해본다.

1,2,3차는 모양이 거의 비슷하다. 2,3차로 표현하기보단 그냥 1차로 표현하는 것이 차라리 나아보인다.
15차는 over fitting이 우려된다.
어떤 모델을 선택할지는 결국 분석하는 사람의 몫이라고 한다.
<prophet모듈을 이용한 forecast 예측>
위 예제 이어서..
pinkwink_web의 date컬럼은 2017. 8. 15. 형식으로 저장돼 있다.
pandas의 to_datetime으로 제대론된 시계열 형식으로 바꿔준다. (ds컬럼은 date series의미)
df = pd.DataFrame({'ds':pinkwink_web.index, 'y':pinkwink_web['hit']})
df.reset_index(inplace=True)
df['ds'] = pd.to_datetime(df['ds'],format="%y. %m. %d.")
del df['date']
그리고 Prophet함수를 사용할 때 주기성이 연단위로 있다고 알려준다.
m = Prophet(yearly_seasonality=True)
m.fit(df)
Prophet객체의 make_future_dataframe을 이용해서 향후 60일간의 데이터를 예측하는 건 다음과 같이 할 수 있다.

예측한 데이터 전체를 forecast 변수에 둔다.

Prophet객체의 plot메서드로 출력하면 2017년말 6월까지의 데이터 이후 약 2개월의 예측 결과가 나타난다.

Prophet객체의 plot_componets로 여러 결과를 얻을 수 있다.
전체적인 트래픽 경향, 요일별 트래픽 경향, 월별 트래픽 경향 순이다.

방문자수는 점차 증가하고 있으며, 토/일 방문자가 적고, 방학시즌의 방문자가 적다는 것을 알 수 있다.
이런 과정을 시즌별 시계열 데이터 분석(Seasonal Time Series Data Analysis)라고 한다.
<Seasonal 시계열 분석으로 주식 데이터 분석하기>
pandas의 DatatReader함수는 구글이 제공하는 주가 정보를 받아올 수 있다.
근데 구글에서 제공하는 부분이 현재 오류가 생겨 야후에서 받아오는 것으로 한다.
기아자동차의 2000년 1월 4일부터 2020년 8월 4일까지의 주가 정보를 받아서 종가 기준으로 그래프를 그린다.

2012년 이후 하락세이다. 일부 데이터로 forecast를 수행해보자.
이전에 블로그 웹 트래픽을 분석한 것처럼 별도로 데이터 프레임을 만든다.

그리고 1년 후, 즉 2020년 12월 31일까지의 정보를 예측해본다.

참고로 forecast의 컬럼들은 다음과 같다. 총 22개 컬럼으로 원하는 것만 사용하면 된다.

그래프를 그려보면 다음과 같다. 어느정도 경향을 예측해주긴 하는 것으로 보인다.
(파란선이 예측값이다.)

plot_components로 경향을 파악할 수 있다.
전체적인 흐름, 주간 데이터, 월별 데이터를 볼 수 있다.
12년 기점으로 하락세, 화,수요일 가격이 비교적 높음, 1,2월의 주가가 낮다는 경향을 알 수 있다.

<Growth model과 holiday forecast>
prophet 튜토리얼에 나오는 예제. 예측함수가 로그함수형태일 때
튜토리얼이 배포하는 데이터.
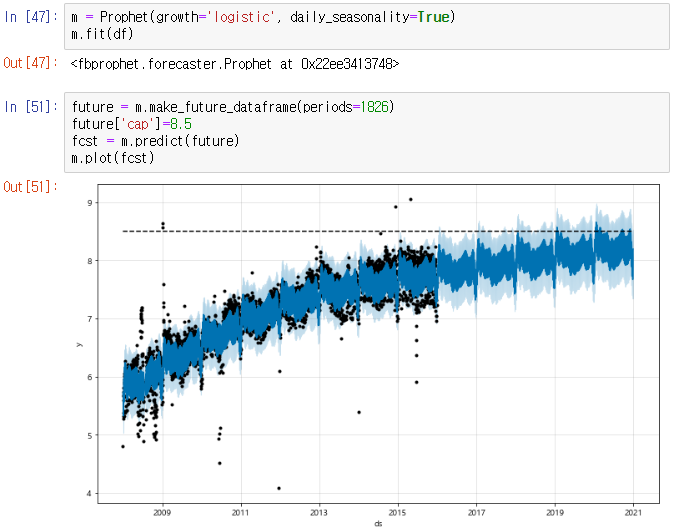
이 데이터는 주기성을 띠면서 점점 성장하는 모습의 데이터이다. 그 모양이 마치 성장(growth)하면서 로그함수(logistic)의 모양과 같다. 파란부분이 예측값이다.
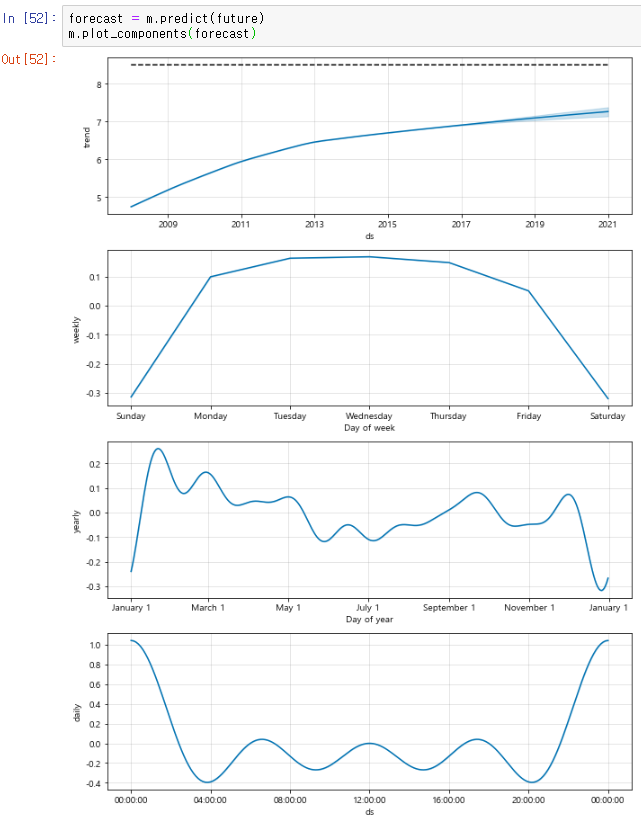
plot_components를 조사해보면 다음과 같다.
<정리>
시계열 데이터에서 예측하기
1. numpy사용
datetime대신 같은 크기의 리스트(예제에선 np.arange로 생성)를 x축으로 하여
polyfit으로 가중치벡터를 만들고 poly1d로 예측함수를 만들어서 예측
2. Prophet모듈을 이용
1) Pandas의 datetime과 그때의 값을 컬럼으로 갖는 DataFrame을 생성한다.
2) Prophet 객체를 1)의 DataFrame으로 만든다.
m = Prophet(yearly_seasonality=True)
m.fit(df)
3) Prophet 객체의 make_future_dataframe 메서드로 향후 i일 간 datetime만을 갖는 데이터프레임 'future'를 만든다.
(이 때 future은 datetime이 담긴 컬럼 하나만 갖는다.)
future = m.make_future_dataframe(periods=60)
4) 3)에서 만든 DataFrame객체 future를 Prophet 객체의 메서드 predict에 넘겨서 예측값을 만든다.
forecast = m.predict(future)
'ML&DATA > 파이썬으로 데이터 주무르기' 카테고리의 다른 글
| 셀프주유소는 정말 저렴할까 (0) | 2020.08.14 |
|---|---|
| 영화별 날짜 변화에 따른 평점 변화 확인하기 (0) | 2020.08.11 |
| 네이버 영화 홈페이지에서 영화의 평점 변화 정리하기 (0) | 2020.08.11 |
| 시카고 샌드위치 맛집 분석 (0) | 2020.08.08 |
| 서울시 구별 CCTV 현황 분석 (0) | 2020.07.29 |



