<목표>
시카고 샌드위치 맛집 리스트를 정리
https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/
위 사이트 하단부의 샌드위치집 순위를 csv파일로 정리해서 시각화하는 것
1. 가게이름, 가게 메인메뉴, 가게 리뷰 페이지(링크url)를 정리
2. 추가로 음식점의 주소, 메인메뉴의 가격도 포함
<데이터 가져오기>
데이터를 인터넷에서 직접 얻어서 사용
홈페이지 하단부의 top50 샌드위치 집이 소개돼 있다. 각 항목마다 <목표>
시카고 샌드위치 맛집 리스트를 정리
https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/
위 사이트 하단부의 샌드위치집 순위를 csv파일로 정리해서 시각화하는 것
가게이름, 가게 메인메뉴, 가게 소개 페이지를 정리하는 것이 목표
<데이터 가져오기>
데이터를 인터넷에서 직접 얻어서 사용
홈페이지 하단부의 top50 샌드위치 집이 소개돼 있다. 각 항목마다 링크가 걸려있는데, 그 링크엔 리뷰와 해당 음식점의 홈페이지 등의 정보가 있다. (12년도 자료라 음식점 홈페이지 대부분이 없어진듯)

크롬 개발자도구로 html상 태그와 클래스를 확인해보면 sammy 클래스의 div마다 총 50개의 항목이 담겨있는 것을 볼 수 있다.

urlopen으로 인터넷에서 해당 홈페이지의 html을 받아서 BeautifulSoup객체를 만든다.
<데이터 추출, 정리>
각 항목 당
랭킹은 sammyRank클래스,
메인메뉴와 가게이름은 sammyListing클래스,
리뷰 페이지는 a태그에 들어있다.

이를 50개 항목에 대해 모두 받아서 rank, main_menu, cafe_name, url_add 리스트에 넣는 코드는 다음과 같다.
from urllib.parse import urljoin
import re
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all('div', 'sammy')
for item in list_soup:
rank.append(item.find(class_='sammyRank').get_text())
tmp_string = item.find(class_='sammyListing').get_text()
main_menu.append(re.split(('\n|\r\n'), tmp_string)[0])
cafe_name.append(re.split(('\n|\r\n'), tmp_string)[1])
url_add.append(urljoin(url_base, item.find('a')['href']))
이제 이 리스트를 pandas에 넣는다.
컬럼 순서도 보기좋게 바꿔준다.(rank, cafe, menu, url순)

추가로 소개 페이지의 정보를 더 읽어올 수 있다.
1등 소개 페이지의 일부를 캡쳐한 것인데, 하이라이트 한 부분이 원하는 정보이다. 가격,주소,전화번호, 음식점 홈페이지정보가 포함돼 있다. html코드상엔 태그 p, 클래스 addy에 있다.

이 홈페이지를 파이썬 코드로 접근한다.



가격은 맨 앞, 홈페이지는 맨 뒤, 전화번호는 두번째 뒤, 주소는 나머지라는 것을 알 수 있다.
주소와 가격만 가져간다.
주소는 price_tmp.split()[1:-2]로 나타낼 수 있는 데 이를 이어서 하나의 문자열로 만들고 싶다면 join을 쓰면된다.
'구분자'.join(리스트)꼴로 사용한다.

DataFrame에 저장된 url을 각각 읽으면서 메인메뉴의 가격과 해당 음식점의 주소를 price,address리스트에 추가하는 코드

DataFrame엔 순위, 음식점이름, 메인메뉴, 가격, 주소만 남긴다.

3장의 메인 주제는 끝.
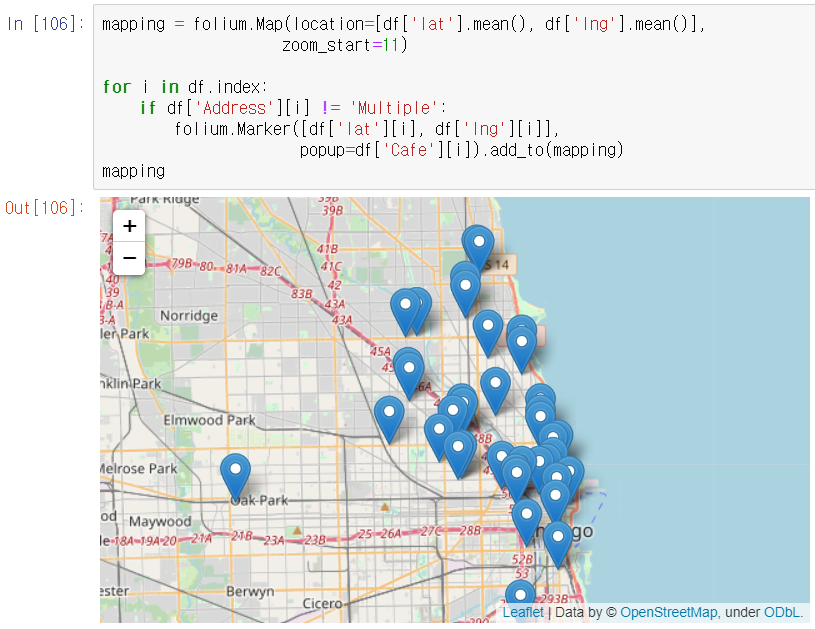
folium으로 지도에 50가지 음식점들의 위치를 Marker로 띄우는 예제
address를 gmaps에서 검색해서 위도와 경도를 받아와 DataFrame에 추가한다.
from tqdm import tqdm_notebook
lat = []
lng = []
for i in tqdm_notebook(df.index): #진행상태 표시위함
if df['Address'][i] != 'Multiple':
target_name = df['Address'][i] + ', ' + 'Cicago'
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get('geometry')
lat.append(location_output['location']['lat'])
lng.append(location_output['location']['lng'])
else:
lat.append(np.nan)
lng.append(np.nan)
df['lat'] = lat
df['lng'] = lng
df.head()
Dataframe의 위도평균과 경도평균좌표를 folium.Map으로 넘겨서 지도를 가져온다. 마커도 찍어준다.
'ML&DATA > 파이썬으로 데이터 주무르기' 카테고리의 다른 글
| 셀프주유소는 정말 저렴할까 (0) | 2020.08.14 |
|---|---|
| 시계열 데이터 다루기 (0) | 2020.08.11 |
| 영화별 날짜 변화에 따른 평점 변화 확인하기 (0) | 2020.08.11 |
| 네이버 영화 홈페이지에서 영화의 평점 변화 정리하기 (0) | 2020.08.11 |
| 서울시 구별 CCTV 현황 분석 (0) | 2020.07.29 |



